Pytorch实现Transformer
Transformer是当代自然语言处理领域不可或缺的模型。本文作者最近学习大语言模型,而Transformer就是大语言模型的基础,所以书写本文通过PyTorch实现Transformer.
Preparing
首先,先导入所需要的包:
import torch
from torch import nn
from torch import optim
from torch.utils import data as Data
import numpy as np
后面需要使用一些有关Transformer的超参数,所以在开头先定义出来:
d_model = 512
max_len = 1024
d_ff = 2048
d_k = d_v = 64
n_layers = 6
n_heads = 8
p_drop = 0.1
变量名依次是:
- d_model: Embedding的大小
- max_len: 输入序列的最长大小
- d_ff: 前馈神经网络的隐藏层大小,一般是 d_model的四倍
- d_k, d_v : 自注意力中K和V的维度, Q的维度直接用K的维度代替,因为这两者必须始终相等
- n_layers: Encoder和Decoder的层数
- n_heads: 自注意力多头的头数
- p_drop: Dropout的概率
Mask
Mask分为两种,一种是因为在数据中使用了padding,不希望pad被加入到注意力中进行计算的Pad Mask for Attention,还有一种是保证Decoder自回归信息不泄露的Subsequent Mask for Decoder。
Pad Mask for Attention
为了方便,假设 在字典中的index是0,遇到输入为0直接将其标为True。
def get_attn_pad_mask(seq_q, seq_k):
'''
Padding, because of unequal in source_len and target_len.
parameters:
seq_q: [batch, seq_len]
seq_k: [batch, seq_len]
return:
mask: [batch, len_q, len_k]
'''
batch, len_q = seq_q.size()
batch, len_k = seq_k.size()
pad_attn_mask = seq_k.data.eq(0).unsqueeze(1)
return pad_attn_mask.expand(batch, len_q, len_k)
在Encoder和Decoder中使用Mask的情况可能各有不同:
- 在Encoder中使用Mask, 是为了将
encoder_input中没有内容而打上PAD的部分进行Mask, 方便矩阵运算. - 在Decoder中使用Mask, 可能是在Decoder的自注意力对
decoder_input的PAD进行Mask, 也有可能是对Encoder - Decoder自注意力时对encoder_input和decoder_input的PAD进行Mask
Subsequent Mask for Decoder
该Mask是为了防止Decoder的自回归信息泄露而生的Mask, 直接生成一个上三角矩阵即可:
def get_attn_subsequent_mask(seq):
'''
Build attention mask matrix for decoder when it autoregressing.
parameters:
seq: [batch, target_len]
return:
subsequent_mask: [batch, target_len, target_len]
'''
attn_shape = [seq.size(0), seq.size(1), seq.size(1)] # [batch, target_len, target_len]
subsequent_mask = np.triu(np.ones(attn_shape), k=1) # [batch, target_len, target_len]
subsequent_mask = torch.from_numpy(subsequent_mask)
return subsequent_mask # [batch, target_len, target_len]
Positional Encoding
在Transformer中, 使用的是绝对位置编码, 用于传输给模型Self - Attention所不能传输的位置信息, 编码使用正余弦公式实现:
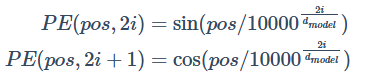
class PositionalEncoding(nn.Module):
def __init__(self, d_model, drop_out=0.1, max_len=1024):
super(PositionalEncoding, self).__init__()
self.dropout = nn.Dropout(p = p_drop)
positional_encoding = torch.zeros(max_len, d_model)
position = torch.arange(0, max_len).float().unsqueeze(1)
div_term = torch.exp(torch.arange(0, d_model, 2).float() * (-torch.log(torch.Tensor([10000])) / d_model))
positional_encoding[:, 0::2] = torch.sin(position * div_term)
positional_encoding[:, 1::2] = torch.cos(position * div_term)
positional_encoding = positional_encoding.unsqueeze(0).transpose(0, 1)
self.register_buffer('pe', postional_encoding)
def forward(self, x):
x = x + self.pe[:x.size(0), ...]
return self.dropout(x)

Feed Forward Neural Network
在Transformer中, Encoder或者Decoder每个Block都需要用一个前馈神经网络来添加非线性:
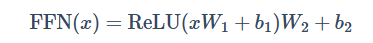
注意, 这里它们都是有偏置的, 而且这两个Linear可以用两个1×1 的卷积来实现:
class FeedForwardNetwork(nn.Module):
'''
using nn.Conv1d replace nn.Linear to implements FFN
'''
def __init__(self):
super(FeedForwardNetwork, self).__init__()
# self.ff1 = nn.Linear(d_model, d_ff)
# self.ff2 = nn.Linear(d_ff, d_model)
self.ff1 = nn.Conv1d(d_model, d_ff, 1)
self.ff2 = nn.Conv1d(d_ff, d_model, 1)
self.relu = nn.Relu()
def forward(self, x):
# x: [batch, seq_len, d_model]
residual = x
x = x.transpose(1, 2)
x = self.ff1(x)
x = self.relu(x)
x = self.ff2(x)
x = x.transpose(1, 2)
return self.layer_norm(residual + x)
作为一个子层, 不要忘记Transformer中提到的Residual Connection和Layer Norm.
我选择用两个卷积代替Linear. 在nn.Conv1d中, 要求数据的规格为[batch, x, ...], 我们是要对d_model 上的数据进行卷积, 所以还是需要transpose一下
Multi - Head Attention
先说多头注意力, 因为多头注意力能够决定缩放点积注意力的输入大小. 作为一个子层, 其中的Residual Connection和Layer Norm是必须的.
多头注意力是多个不同的头来获取不同的特征, 类似于多个卷积核所达到的效果. 在计算完后通过一个Linear调整大小:

多头注意力在Encoder和Decoder中的使用略有区别, 主要区别在于Mask的不同. 我们前面已经实现了两种Mask函数, 在这里会用到.
多头注意力实际上不是通过弄出很多大小相同的矩阵然后相乘来实现的, 只需要合并到一个矩阵进行计算:
class MultiHeadAttention(nn.Module):
def __init__(self, n_heads = 8):
super(MultiHeadAttention, self).__init__()
self.n_heads = n_heads
self.W_Q == nn.Linear(d_model, d_k * n_heads, bias = False)
self.W_K == nn.Linear(d_model, d_k * n_heads, bias = False)
self.W_V == nn.Linear(d_model, d_v * n_heads, bias = False)
self.fc = nn.Linear(d_v * n_heads, d_model, bias)
self.layer_norm = nn.LayerNorm(d_model)
def forward(self, input_Q, input_K, input_V, attn_mask):
residual, batch = input_Q, input_Q.size(0)
Q = self.W_Q(input_Q).view(batch, -1, n_heads, d_k).transpose(1, 2)
K = self.W_K(input_K).view(batch, -1, n_heads, d_k).transpose(1, 2)
V = self.W_V(input_V).view(batch, -1, n_heads, d_v).transpose(1, 2)
attn_mask = attn_mask.unsqueeze(1).repeat(1, n_heads, 1, 1)
prob, attn = ScaledDotProductAttention()(Q, K, V, attn_mask)
prob = prob.transpose(1, 2).contiguous()
prob = prob.view(batch, -1, n_heads * d_v).contiguous()
output = self.fc(prob) # [batch, len_q, d_model]
return self.layer_norm(residual + output), attn
提两个非常重要的点:
- 在拆维度时不要破坏维度原来本身的意义.
- 虽然新版本已经有
reshape函数可以用了, 但是仍然不要忘记,transpose后如果接permute或者view必须要加contiguous, 这是数据真实存储连续与否的问题, 请参见Pytorch之张量基础操作中的维度变换部分
Scaled DotProduct Attention
Tranformer中非常重要的概念, 缩放点积注意力, 公式如下:
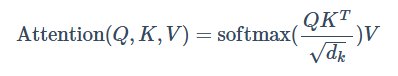
实现起来非常简单, 只需要把Q, K两个矩阵一乘, 然后再缩放, 过一次Softmax, 再和V乘下:
class ScaledDotProductAttention(nn.Module):
def __init__(self):
super(ScaledDotProductAttention, self).__init__()
def forward(self, Q, K, V, attn_mask):
'''
Q: [batch, n_heads, len_q, d_k]
K: [batch, n_heads, len_k, d_k]
V: [batch, n_heads, len_v, d_v]
attn_mask: [batch, n_heads, seq_len, seq_len]
'''
scores = torch.matmul(Q, K.transpose(-1, -2)) / np.sqrt(d_k) # [batch, n_heads, len_q, len_k]
scores.masked_fill_(attn_mask, -1e9)
attn = nn.Softmax(dim=-1)(scores) # [batch, n_heads, len_q, len_k]
prob = torch.matmul(attn, V) # [batch, n_heads, len_q, d_v]
return prob, attn
masked_fill_能把传进来的Mask为True的地方全都填充上某个值, 这里需要用一个很大的负数来保证ex→0, 使得其在Softmax 中可以被忽略
Encoder
先写出Encoder的每个Layer, 由多头注意力和FFN组成:
class EncoderLayer(nn.Module):
def __init__(self):
super(EncoderLayer, self).__init__()
self.encoder_self_attn = MultiHeadAttention()
self.ffn = FeedForwardNetwork()
def forward(self, encoder_input, encoder_pad_mask):
encoder_output, attn = self.encoder_self_attn(encoder_input, encoder_input, encoder_input, encoder_pad_mask )
encoder_output = self.ffn(encoder_output)
return encoder_output, attn
对于给定的encoder_input和encoder_pad_pask, Encoder应该能够完成整个Block(Layer)的计算流程. 然后实现整个Encoder:
class Encoder(nn.Module):
def __init__(self):
super(Encoder, self).__init__()
self.source_embedding = nn.Embedding(source_vocab_size, d_model)
self.positional_embedding = PositionalEncoding(d_model)
self.layers = nn.ModuleList([EncoderLayer() for layer in range(n_layers)])
def forward(self, encoder_input):
# encoder_input: [batch, source_len]
encoder_output = self.source_embedding(encoder_input) # [batch, source_len, d_model]
encoder_output = self.positional_embedding(encoder_output.transpose(0, 1)).transpose(0, 1) # [batch, source_len, d_model]
encoder_self_attn_mask = get_attn_pad_mask(encoder_input, encoder_input) # [batch, source_len, source_len]
encoder_self_attns = list()
for layer in self.layers:
# encoder_output: [batch, source_len, d_model]
# encoder_self_attn: [batch, n_heads, source_len, source_len]
encoder_output, encoder_self_attn = layer(encoder_output, encoder_self_attn_mask)
encoder_self_attns.append(encoder_self_attn)
return encoder_output, encoder_self_attns
对于整个Encoder, 直接将Token的Index传入Embedding中, 再添入位置编码, 之后就经过多层Transformer Encoder. 在传入Block前, 先需要计算Padding的Mask, 再将上层的输出作为下层输入依次迭代.
Decoder
其实实现了Encoder, Decoder的实现部分都是对应的. 先实现Decoder的Block:
class DecoderLayer(nn.Module):
def __init__(self):
super(DecoderLayer, self).__init__()
self.decoder_self_attn = MultiHeadAttention()
self.encoder_decoder_attn = MultiHeadAttention()
self.ffn = FeedForwardNetwork()
def forward(self, decoder_input, encoder_output, decoder_self_mask, decoder_encoder_mask):
'''
decoder_input: [batch, target_len, d_mdoel]
encoder_output: [batch, source_len, d_model]
decoder_self_mask: [batch, target_len, target_len]
decoder_encoder_mask: [batch, target_len, source_len]
'''
# masked mutlihead attention
# Q, K, V all from decoder it self
# decoder_output: [batch, target_len, d_model]
# decoder_self_attn: [batch, n_heads, target_len, target_len]
decoder_output, decoder_self_attn = self.decoder_self_attn(decoder_input, decoder_input, decoder_input, decoder_self_mask)
# Q from decoder, K, V from encoder
# decoder_output: [batch, target_len, d_model]
# decoder_encoder_attn: [batch, n_heads, target_len, source_len]
decoder_output, decoder_encoder_attn = self.encoder_decoder_attn(decoder_output, encoder_output, encoder_output, decoder_encoder_mask)
decoder_output = self.ffn(decoder_output) # [batch, target_len, d_model]
return decoder_output, decoder_self_attn, decoder_encoder_attn
与Encoder相对应, 只不过因为多了一个Encoder - Decoder自注意力, 所以需要额外计算一个Encoder - Decoder的Mask. 然后写出整个Decoder:
class Decoder(nn.Module):
def __init__(self):
super(Decoder, self).__init__()
self.target_embedding = nn.Embedding(target_vocab_size, d_model)
self.positional_embedding = PositionalEncoding(d_model)
self.layers = nn.ModuleList([DecoderLayer() for layer in range(n_layers)])
def forward(self, decoder_input, encoder_input, encoder_output):
'''
decoder_input: [batch, target_len]
encoder_input: [batch, source_len]
encoder_output: [batch, source_len, d_model]
'''
decoder_output = self.target_embedding(decoder_input) # [batch, target_len, d_model]
decoder_output = self.positional_embedding(decoder_output.transpose(0, 1)).transpose(0, 1) # [batch, target_len, d_model]
decoder_self_attn_mask = get_attn_pad_mask(decoder_input, decoder_input) # [batch, target_len, target_len]
decoder_subsequent_mask = get_attn_subsequent_mask(decoder_input) # [batch, target_len, target_len]
decoder_encoder_attn_mask = get_attn_pad_mask(decoder_input, encoder_input) # [batch, target_len, source_len]
decoder_self_mask = torch.gt(decoder_self_attn_mask + decoder_subsequent_mask, 0)
decoder_self_attns, decoder_encoder_attns = [], []
for layer in self.layers:
# decoder_output: [batch, target_len, d_model]
# decoder_self_attn: [batch, n_heads, target_len, target_len]
# decoder_encoder_attn: [batch, n_heads, target_len, source_len]
decoder_output, decoder_self_attn, decoder_encoder_attn = layer(decoder_output, encoder_output, decoder_self_mask, decoder_encoder_attn_mask)
decoder_self_attns.append(decoder_self_attn)
decoder_encoder_attns.append(decoder_encoder_attn)
return decoder_output, decoder_self_attns, decoder_encoder_attns
和Encoder相对应, 但Decoder和Encoder使用了两个不同的Embedding. 对于Mask, 可以把自回归Mask和Padding Mask用torch.gt整合成一个Mask, 送入其中.
Transformer
里面有一个Encoder, 一个Decoder, 在Decoder端还需要加上投影层来分类:
class Transformer(nn.Module):
def __init__(self):
super(Transformer, self).__init__()
self.encoder = Encoder()
self.decoder = Decoder()
sefl.projection = nn.Linear(d_model, target_vovab_size, bias = False)
def forward(self, encoder_input, decoder_input):
'''
encoder_input: [batch, source_len]
decoder_input: [batch, target_len]
'''
# encoder_output: [batch, source_len, d_model]
# encoder_attns: [n_layers, batch, n_heads, source_len, source_len]
encoder_output, encoder_attns = self.encoder(encoder_input)
# decoder_output: [batch, target_len, d_model]
# decoder_self_attns: [n_layers, batch, n_heads, target_len, target_len]
# decoder_encoder_attns: [n_layers, batch, n_heads, target_len, source_len]
decoder_output, decoder_self_attns, decoder_encoder_attns = self.decoder(decoder_input, encoder_input, encoder_output)
decoder_logits = self.projection(decoder_output) # [batch, target_len, target_vocab_size]
# decoder_logits: [batch * target_len, target_vocab_size]
return decoder_logits.view(-1, decoder_logits.size(-1)), encoder_attns, decoder_self_attns, decoder_encoder_attns
最后对logits的处理是view成了[batch * target_len, target_vocab_size], 前面的大小并不影响我们一会用交叉熵计算损失.