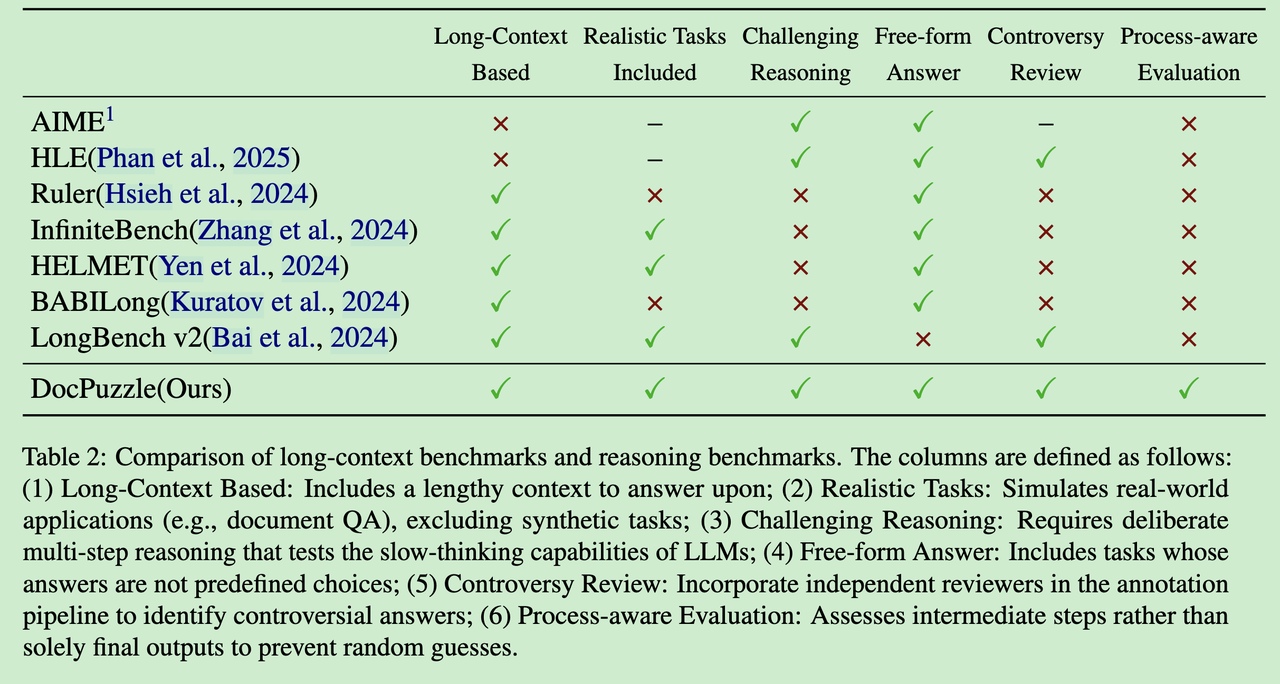
论文概览
论文标题:DocPuzzle: A Process-Aware Benchmark for Evaluating Realistic Long-Context Reasoning Capabilities
主要贡献:提出了一个专门评估大语言模型长文本推理能力的新基准
数据规模:100个专家级问答问题,涵盖5个现实领域
创新点:首创基于清单引导的过程感知评估框架
核心发现:慢思考模型显著优于通用指令模型,蒸馏技术难以保持推理能力泛化性
核心贡献
DocPuzzle 解决了当前长文本推理评估中的三大痛点:
- 真实场景推理:不再局限于数学题和编程题,而是基于现实世界的多领域长文档
- 过程感知评估:首创基于核查清单的评估体系,避免"蒙对答案"的问题
- 高区分度设计:专门针对前沿模型设计,能够有效区分不同模型的推理能力
问题背景:现有评估的三大局限
当前长文本基准的困境
虽然GPT-4、Claude等模型在传统基准上表现亮眼,但当我们深入分析时,发现现有评估体系存在严重问题:
1. 推理过于简化
大多数"推理"任务实际上只是信息检索的伪装:
- 找到文档中的某个句子就能直接回答问题
- 最多需要简单的一两步逻辑运算
- 缺乏真正需要多步骤思考的复杂推理
2. 格式限制带来猜测偏差
为了评估便利,很多基准都采用选择题格式:
- 模型可以通过随机猜测获得25%的准确率
- 即使推理错误,也可能"蒙对"答案
- 无法真正评估推理过程的正确性
3. 领域覆盖过于狭窄
现有基准要么聚焦单一领域,要么过度简化:
- 仅限于文学分析、政策文本等特定垂直领域
- 为了避免争议而排除复杂的现实场景
- 缺乏跨领域的泛化能力评估
核心洞察:什么是真正的长文本推理?
真实世界的长文本推理具有以下特征:
- 多步骤依赖:需要综合文档中多个分散的信息点
- 隐式逻辑链:答案不是直接陈述的,需要推导得出
- 领域知识整合:结合上下文信息和常识进行判断
DocPuzzle正是基于这些特征设计的。
技术方法详解
数据构建:三阶段严格流程
第一阶段:多领域文档收集
我们从五个核心领域精心筛选长文档:
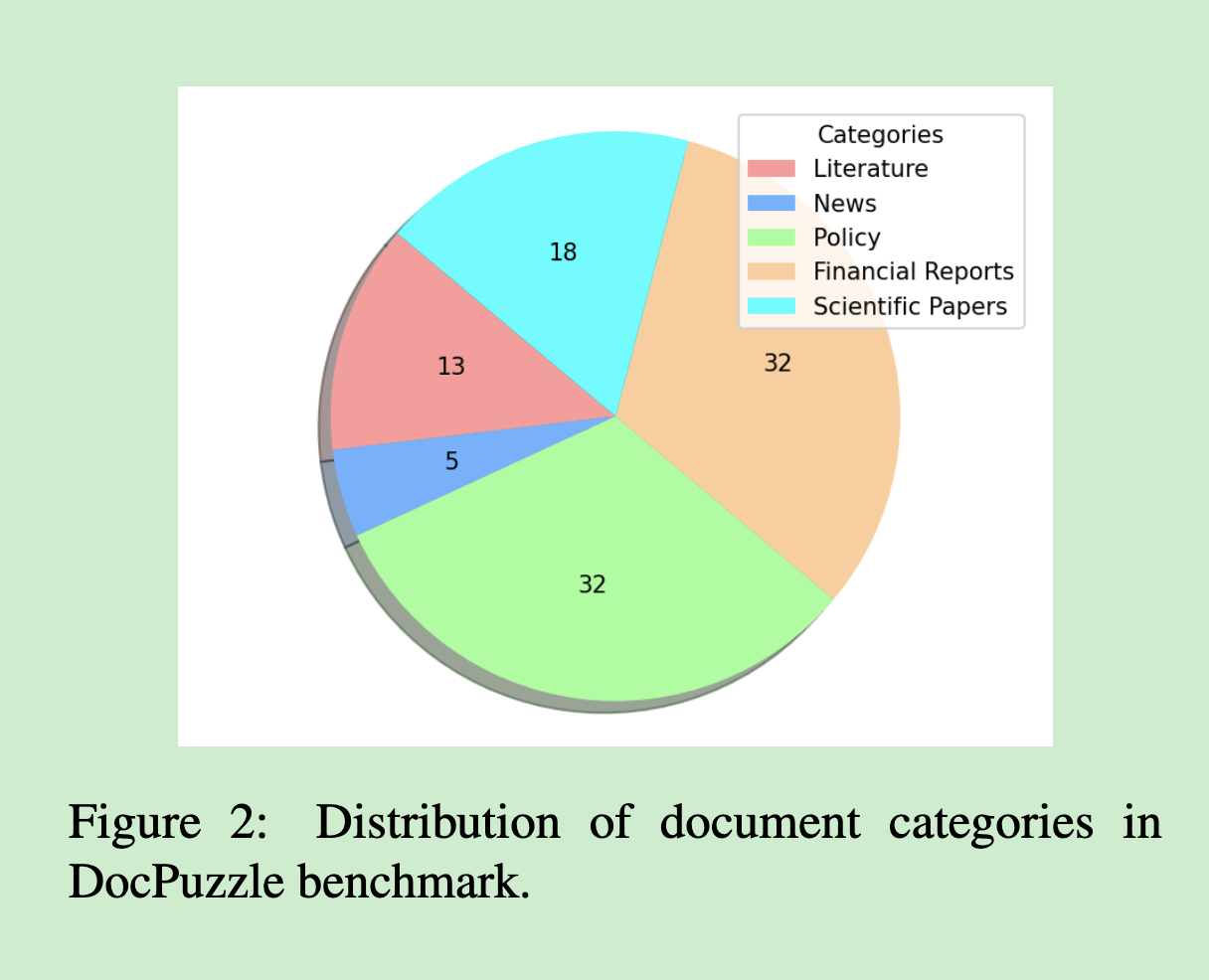
- 文学作品:需要理解复杂的情节发展和人物关系
- 新闻文章:要求时序推理和事件关联分析
- 政策文件:涉及逻辑条件判断和规则适用
- 财务报告:需要数值计算和趋势分析
- 科学论文:要求专业知识理解和因果推理
为什么选择这些领域?
- 覆盖了现实应用中最常见的文档类型
- 每个领域都有其独特的推理模式
- 确保了任务的多样性和挑战性
第二阶段:高质量问题设计
我们建立了严格的标注规范:
1. 上下文依赖推理
- 所有问题必须基于原始文档内容推导
- 禁止仅凭常识或预训练知识就能回答的问题
- 评估的是推理能力,而非记忆能力
2. 多步骤推理复杂度 每个问题至少涉及以下两类推理操作:
- 时序推理:理解事件的先后顺序和因果关系
- 算术推理:进行数值计算和比较分析
- 桥接推理:连接文档中分散的相关信息
- 对比分析:比较不同对象或情况的异同
- 因果推断:分析原因和结果之间的逻辑关系
3. 认知陷阱设计 我们刻意设置一些"陷阱"来测试模型的鲁棒性:
- 相似但不相同的概念
- 容易混淆的时间节点
- 需要仔细计算的数值关系
第三阶段:多轮验证与修订
为了确保问题质量,我们采用了创新的验证机制:
前沿模型预测试
- 使用o1-preview、GPT-4o、QwQ-32B等最强模型测试
- 重点分析所有模型都失败的案例
- 剔除过于简单或过于困难的样本
人工交叉验证
- 多名专家独立解答同一问题
- 出现分歧时进行充分讨论
- 只保留达成稳定共识的样本
创新评估方法:过程感知框架
传统评估的盲点
现有评估方法存在一个致命缺陷:只看结果,不看过程。这就像考试只看答案对错,不看解题步骤一样,很容易被"蒙对"的情况误导。
我们的解决方案:核查清单
对于每个问题,我们都设计了详细的核查清单(Checklist),用来验证推理过程的正确性:
清单内容示例:
- ✅ 是否正确识别了关键信息A和B?
- ✅ 是否正确理解了A和B之间的关系?
- ✅ 计算过程是否正确?(允许合理的舍入误差)
- ✅ 最终结论是否逻辑一致?
评估机制:
- 使用GPT-4o作为评判模型
- 通过三个不同的提示变体进行多数投票
- 运行三次取平均值,确保结果稳定性
这种方法既包容了合理的表达差异,又能严格惩罚逻辑错误。
实验结果:揭示模型能力真相
主要发现一:慢思考模型的显著优势
实验结果清晰地展现了模型间的能力差距:
| 模型类型 | 代表模型 | DocPuzzle得分 |
|---|---|---|
| 慢思考推理 | o1-preview | 69.7% |
| 慢思考推理 | DeepSeek-R1 | 66.3% |
| 通用指令 | Claude 3.5 Sonnet | 57.7% |
| 通用指令 | DeepSeek-V3 | 45.0% |
| 蒸馏模型 | DeepSeek-R1-Distill-Qwen-32B | 41.3% |
关键洞察:
- 专门设计的慢思考模型在复杂推理上确实有显著优势
- 即使是最强的通用指令模型,在多步推理上仍有明显差距
- 这验证了DocPuzzle对真实推理能力的有效评估
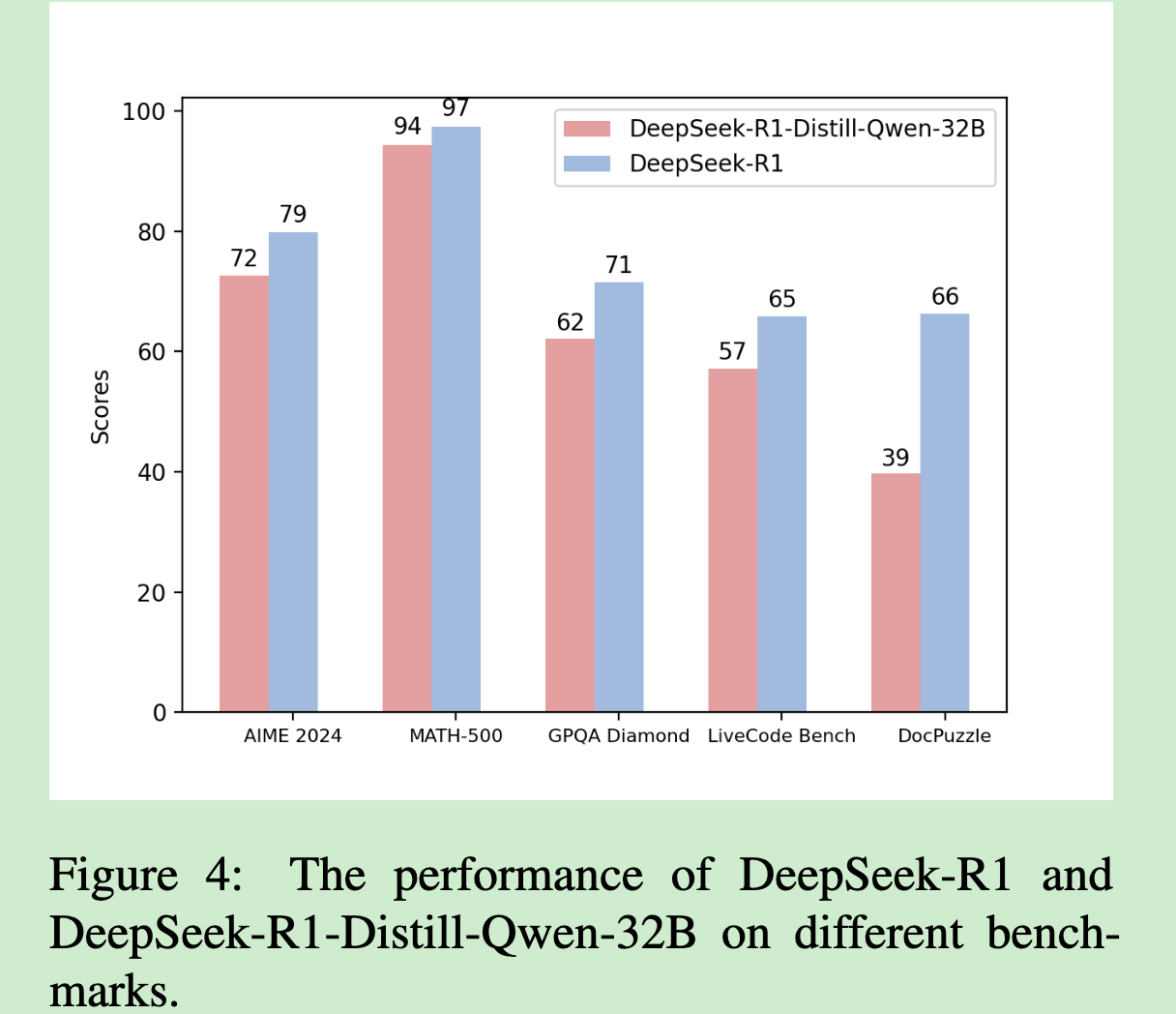
主要发现二:蒸馏技术的局限性
一个令人意外的发现是:蒸馏模型的推理能力泛化性有限。
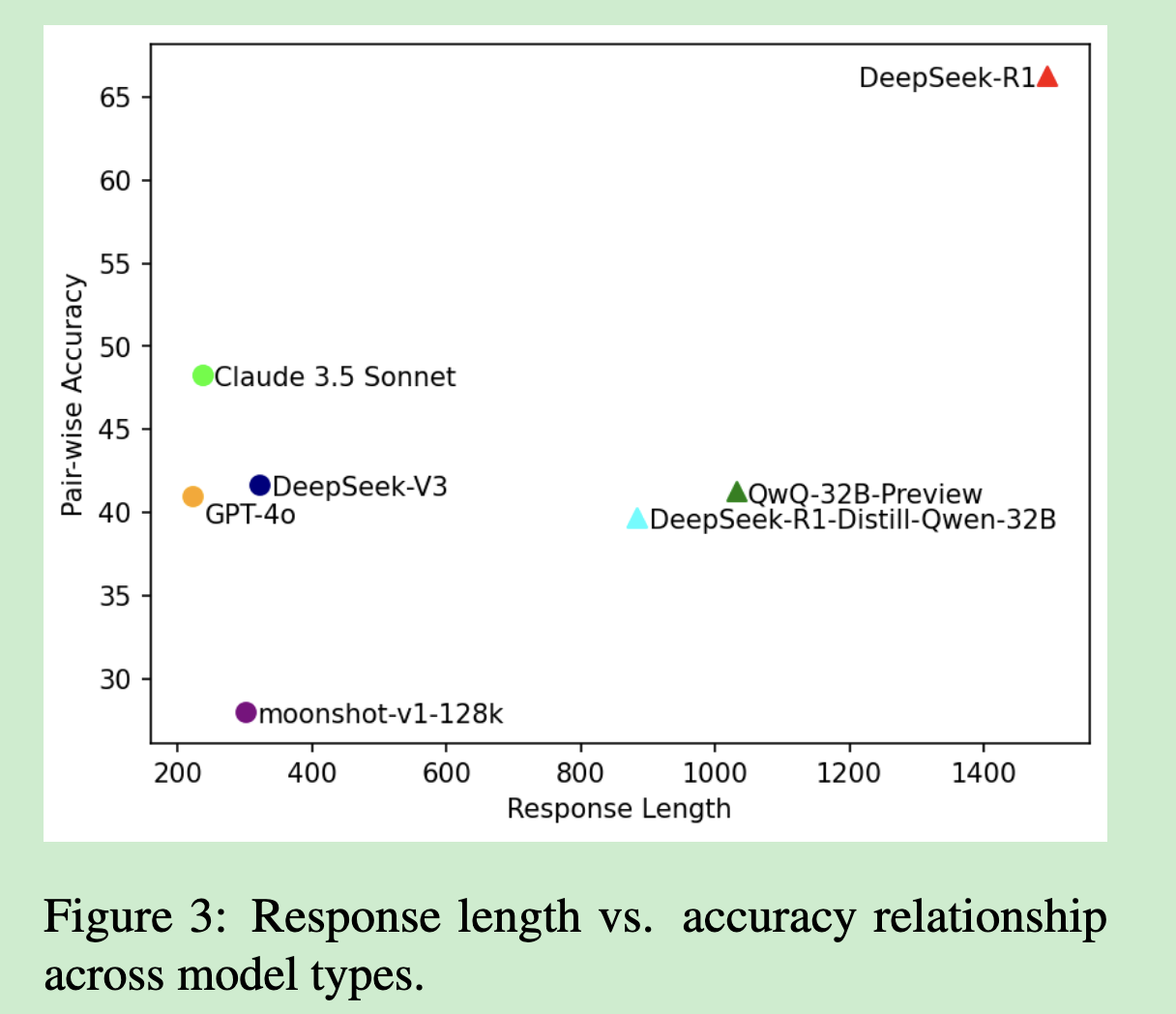
虽然DeepSeek-R1-Distill-Qwen-32B在数学和编程任务上表现良好,但在DocPuzzle上显著落后于教师模型。这说明:
- 蒸馏容易学到表面模式,但难以掌握深层推理逻辑
- 领域特化的推理能力很难通过简单的监督学习传递
- 真正的推理能力可能需要更复杂的训练方法
主要发现三:规模效应的验证
模型规模与推理能力呈现明显的正相关关系:
- Qwen2.5-7B: 20.3%
- Qwen2.5-32B: 35.1%
- Qwen2.5-72B: 39.7%
这验证了在推理任务中,模型容量确实是关键因素。
主要发现四:思维链提示的门槛效应
有趣的是,思维链提示并非对所有模型都有效:
- 强模型受益明显:Claude 3.5 Sonnet和Qwen2.5-72B通过CoT获得显著提升
- 弱模型反而下降:Qwen2.5-7B和moonshot-v1使用CoT后性能下降
- 存在能力门槛:只有当基础得分超过32.7%时,CoT才开始显效
这表明模型需要达到一定的基础推理能力才能有效利用推理路径。
深度分析:模型推理能力的边界
探索能力的悖论
我们通过pass@3指标(3次尝试中至少1次成功)来评估模型的探索潜力:
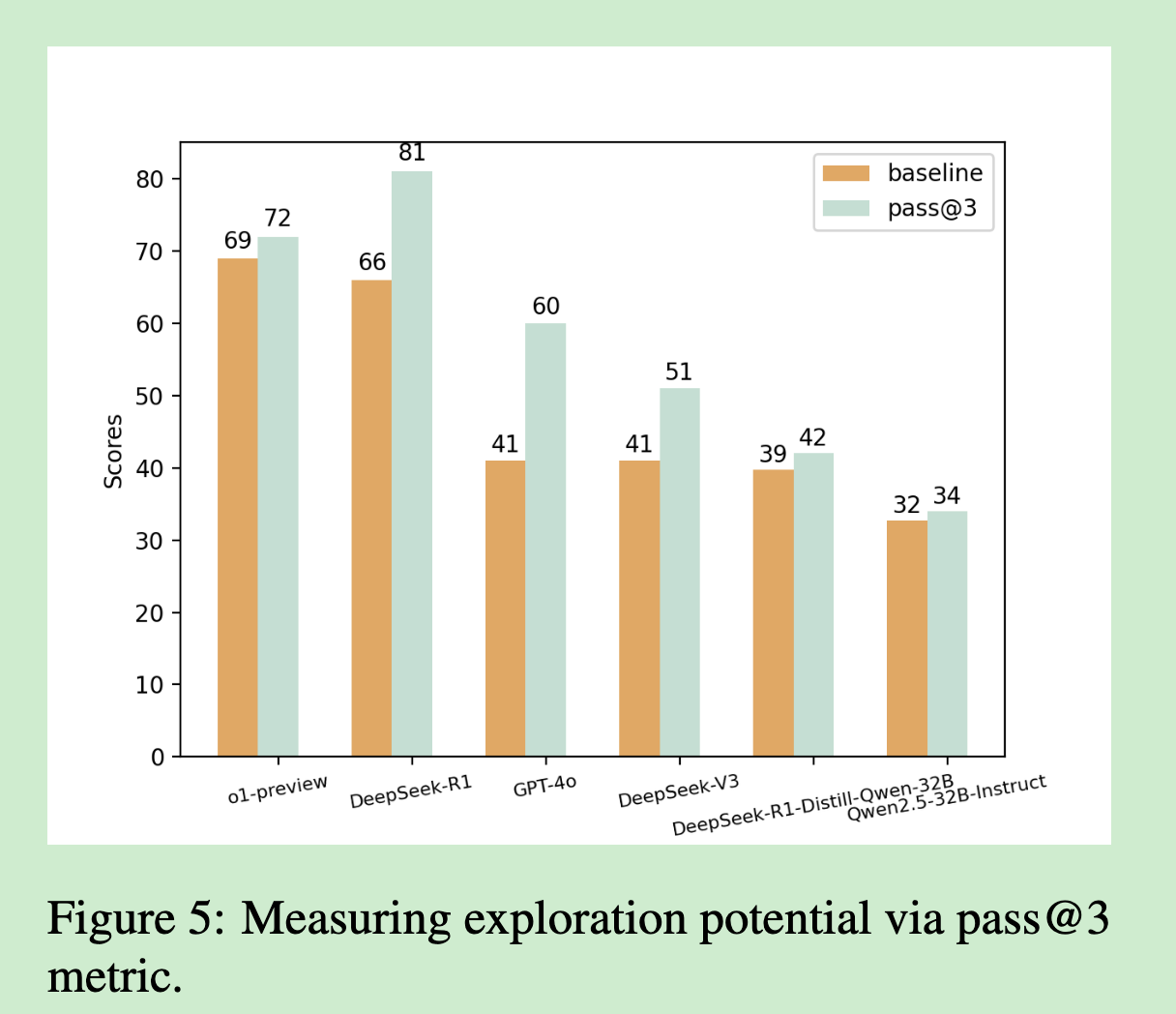
令人意外的是:探索潜力与基础准确率之间没有显著相关性。这意味着:
- 单纯增加尝试次数并不能显著提升复杂推理任务的成功率
- 模型的探索策略可能需要更根本性的改进
典型错误分析:常识推理的盲点
即使是最强的模型也会在看似简单的常识问题上出错:
案例:建筑面积与使用面积
- 常识:建筑面积通常大于使用面积
- 现象:o1-preview和DeepSeek-R1都未能识别这一基础差异
- 启示:基础常识的缺失可能阻碍更深层次的推理
这提醒我们,即使是最先进的模型,在常识推理方面仍有重要的提升空间。
技术创新点
1. 过程感知评估框架
首次提出通过核查清单来评估推理过程,而非仅看最终答案,有效降低了猜测偏差。
2. 现实场景设计
不同于传统的数学或编程题,DocPuzzle基于真实世界的多领域文档,更贴近实际应用需求。
3. 严格的质量控制
通过多轮专家验证和前沿模型预测试,确保每个问题都具有合适的难度和明确的答案。
4. 多维度能力评估
不仅评估最终表现,还从回答长度、探索能力、错误模式等多个角度分析模型特征。
局限性与未来方向
当前挑战
- 样本规模限制:100个样本虽然质量很高,但规模仍然有限
- 中文为主:主要针对中文场景,多语言适用性有待验证
- 评估成本:需要强模型作为评判器,评估成本相对较高
未来展望
- 规模扩展:构建更大规模的高质量推理评估数据集
- 多语言支持:扩展到更多语言和文化背景
- 自动化评估:开发更高效的自动评估方法
- 动态更新:建立持续更新机制,跟上模型发展的步伐
论文翻译:https://dppemvhuzp.feishu.cn/docx/ZyoSd5HRfoyDT8xIk7Ecx12enlf?from=from_copylink