单位: Christophe BAJANa,‡ and Guillaume LAMBARDa,‡
代码:🈚️
原文地址:https://arxiv.org/abs/2501.04277
overview
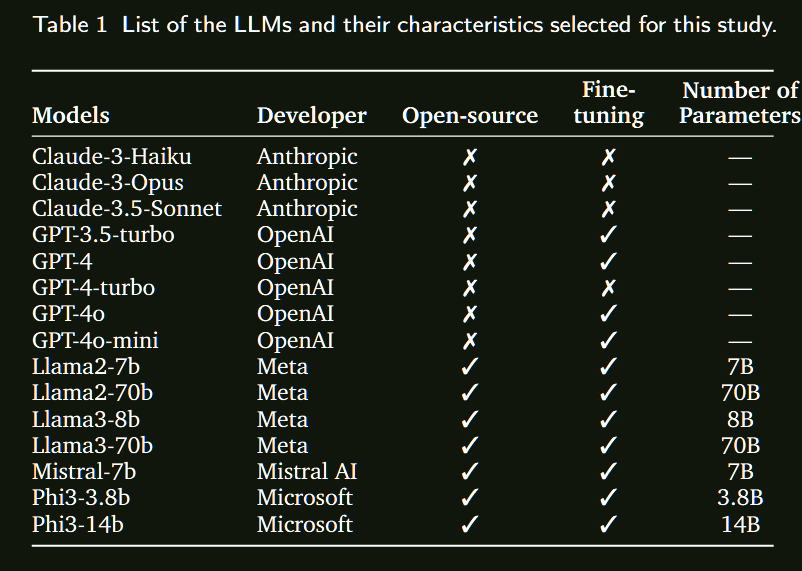
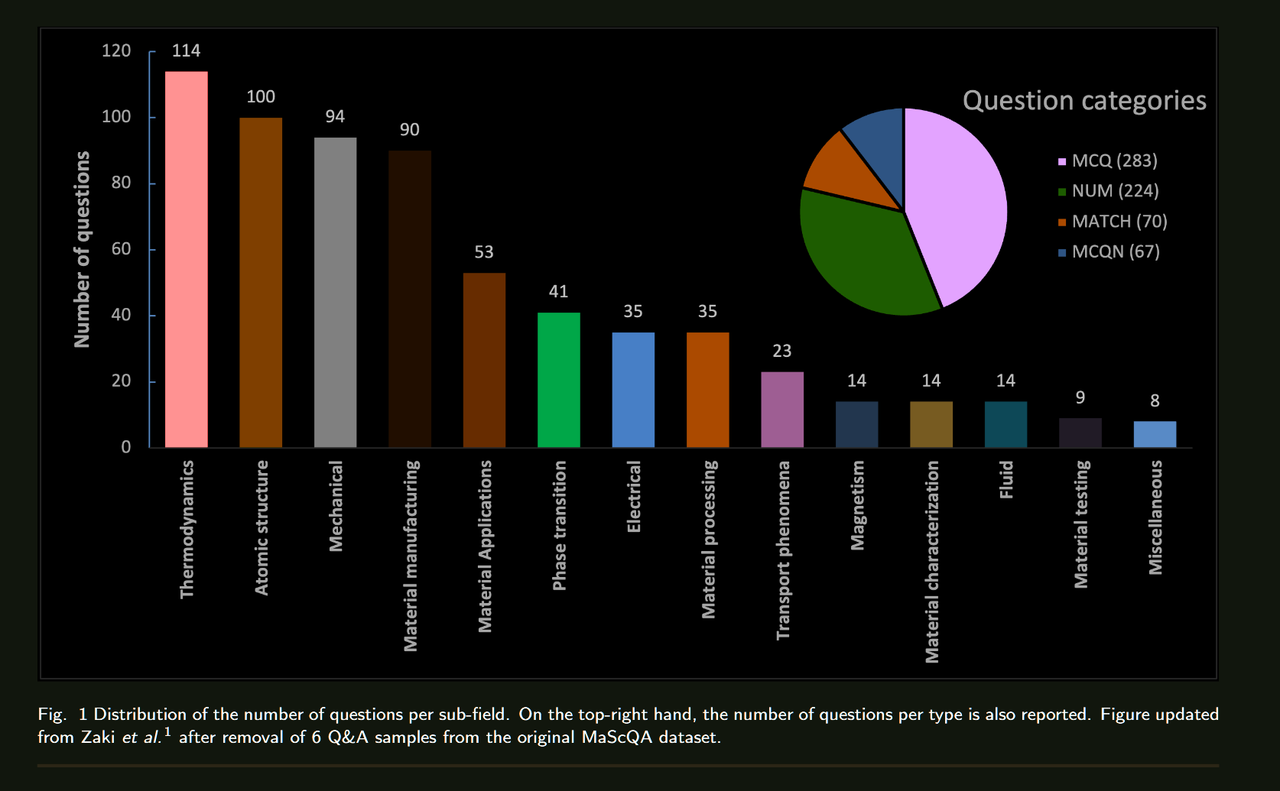
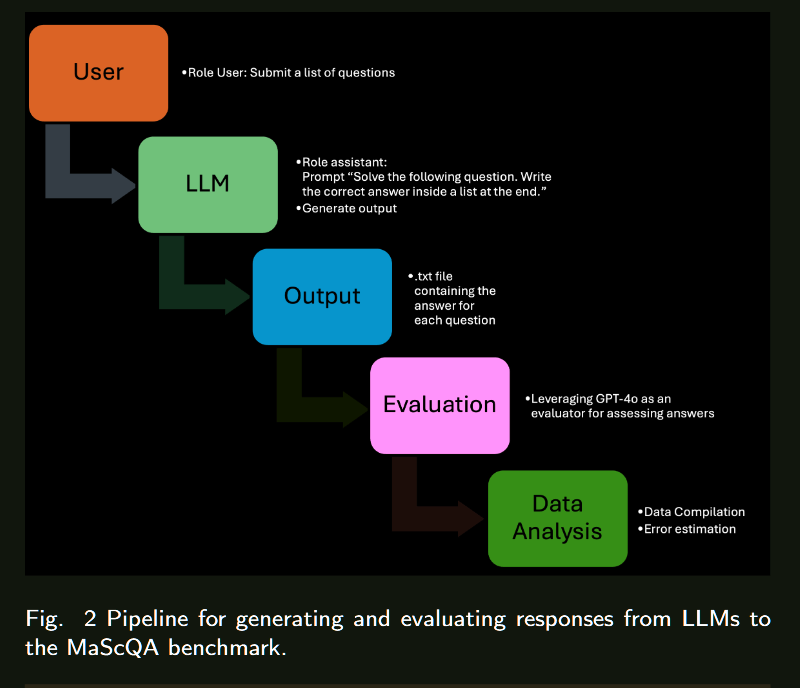
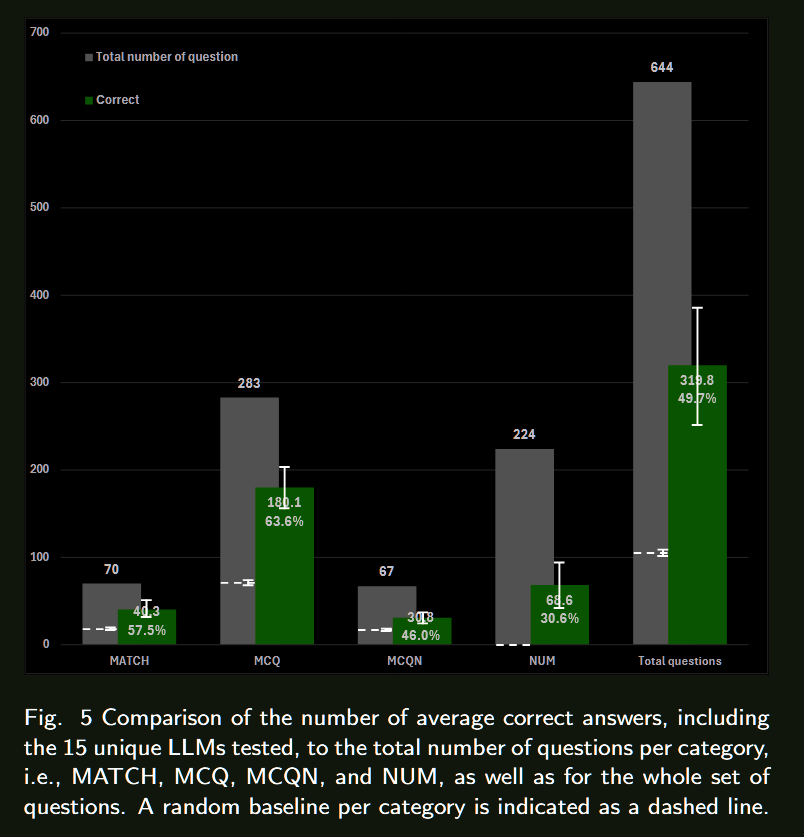
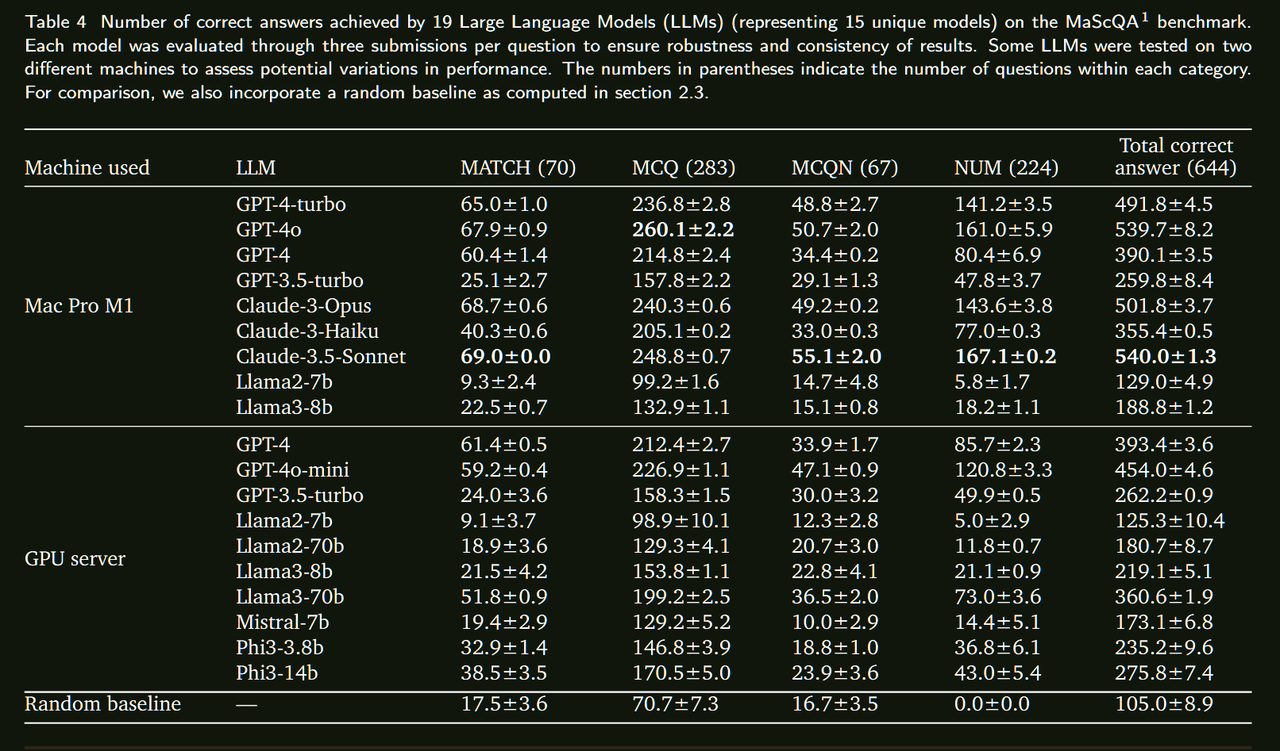
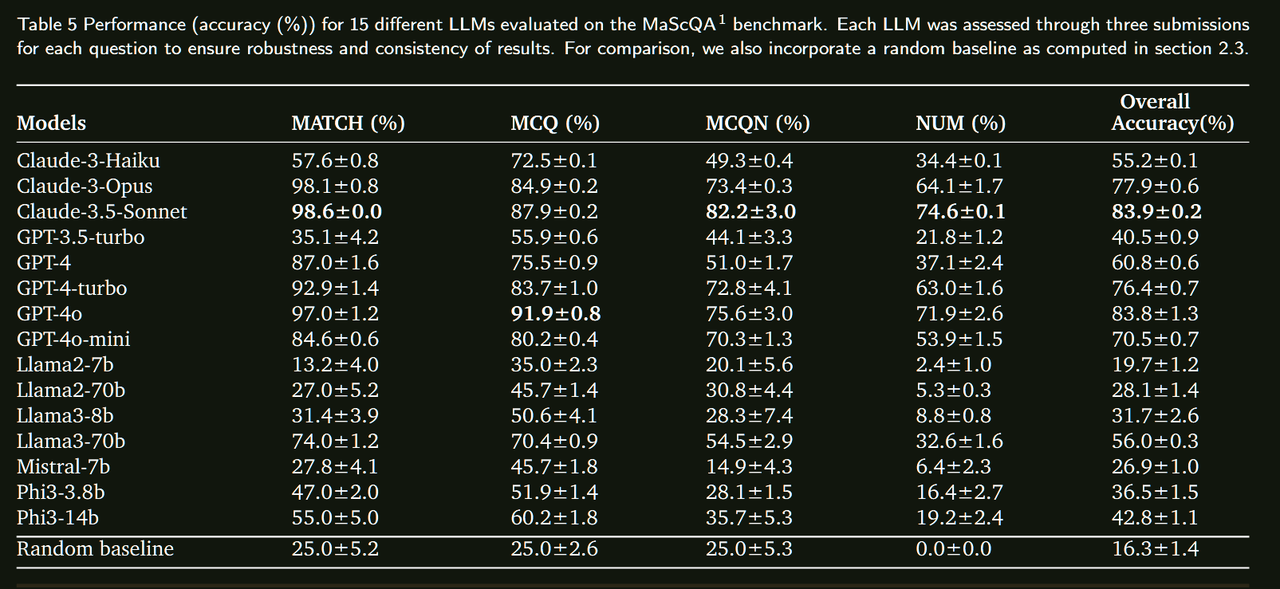
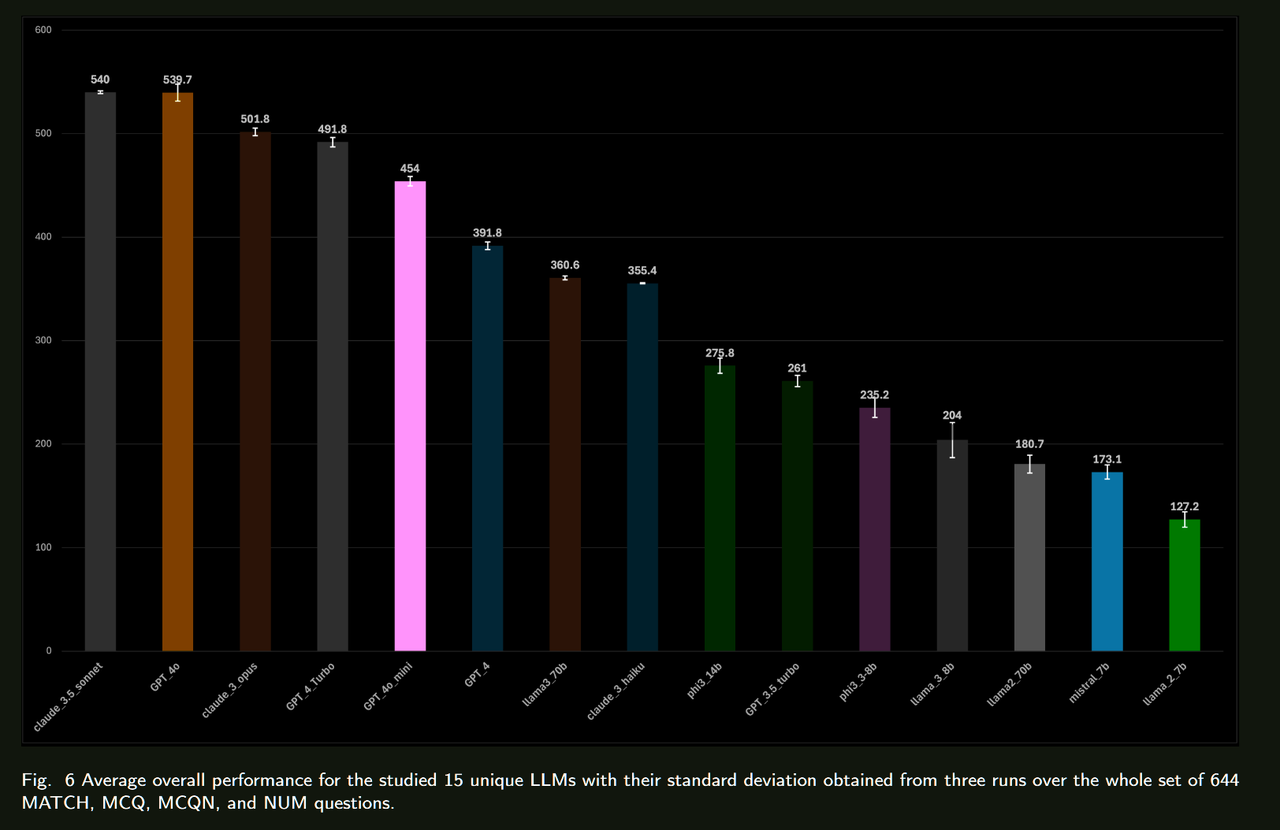
人工智能在各领域的整合正在迅速增加,大型语言模型(LLMs)在众多应用中也变得越来越普遍。这项研究是一个整体项目的一部分,该项目旨在专门在材料科学领域训练一个LLM。为了评估这种专门化训练的影响,必须建立现有LLMs在材料科学中的基线性能。在本研究中,我们使用MaScQA问答(QA)基准评估了15种不同的LLMs。该基准包括来自工程研究生入学考试(GATE)的问题,旨在测试模型在回答与材料科学和冶金工程相关的问题时的能力。我们的结果表明,闭源LLMs,如Claude-3.5-Sonnet和GPT-4o,表现最佳,总体准确率约为84%,而开源模型Llama3-70b和Phi3-14b的准确率分别约为56%和43%。这些发现为LLMs在材料科学QA任务中的原始能力提供了基线,并强调了通过提示工程和微调策略可以为开源模型带来的显著改进。我们预计这项工作将推动LLMs作为材料科学中有价值的助手的采用,展示它们在这一专业领域及相关子领域中的实用性。
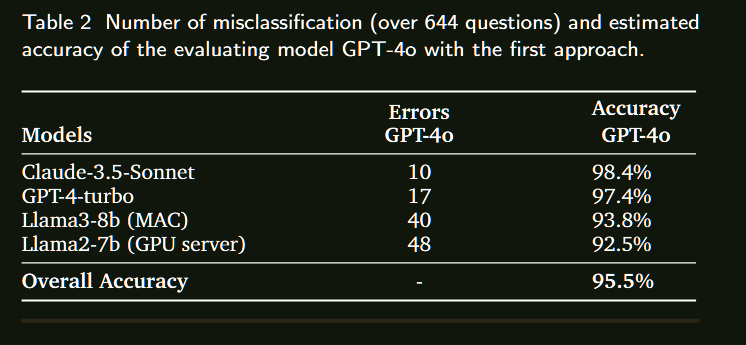
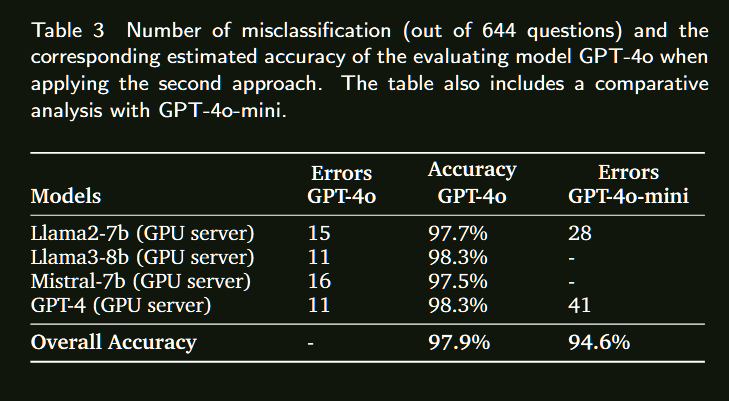
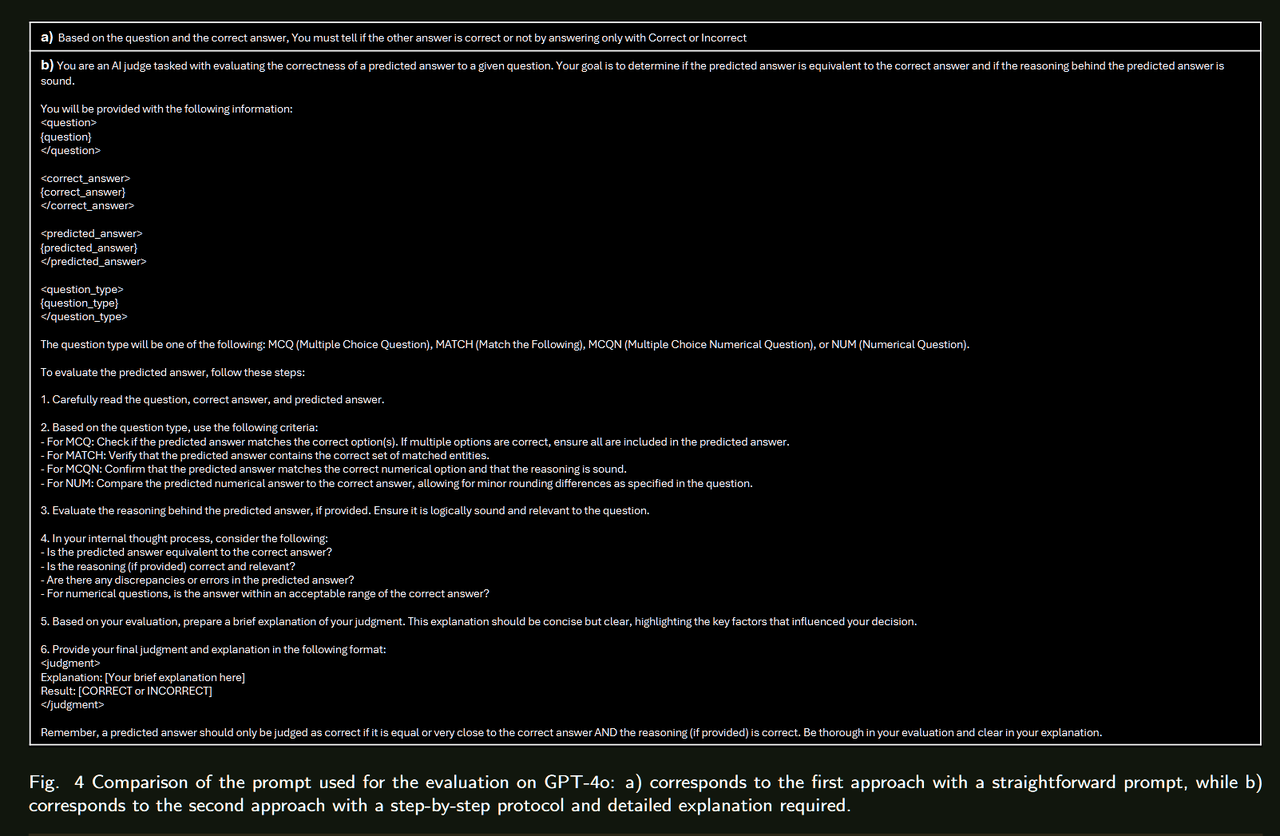
总结来看没有提出太多的方法,只是在一个benchmark上对比了多个开源/闭源模型的表现,直接看表格就行。
论文翻译:https://dppemvhuzp.feishu.cn/docx/EWzQdNfDkoLuDkx2Y2fcDkuLnLh?from=from_copylink