论文概览
论文标题:FollowBench: A Multi-level Fine-grained Constraints Following Benchmark for Large Language Models
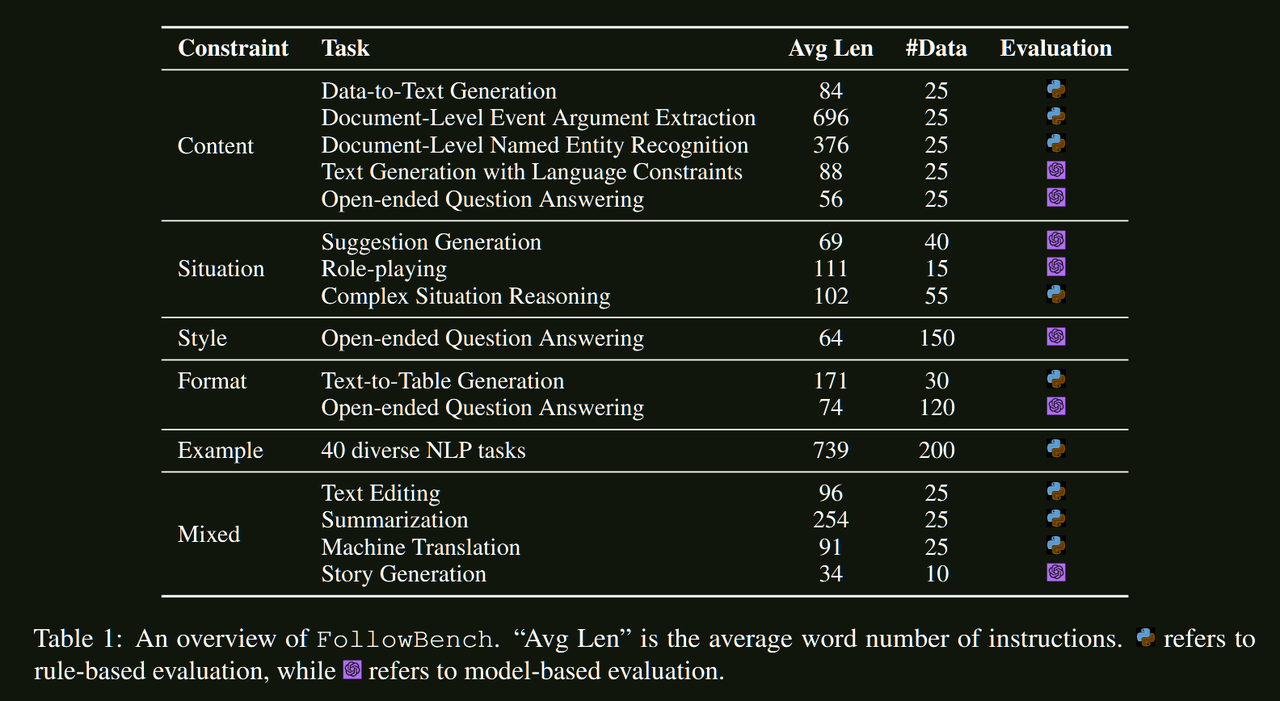
数据规模:820条精心设计的指令,涵盖50+个NLP任务
核心创新:首创多层级细粒度约束遵循评估框架
约束类型:内容、情境、风格、格式、示例五大维度
代码仓库:https://github.com/YJiangcm/FollowBench
关键发现:即使GPT-4也只能稳定遵循约3个约束条件,指令遵循能力提升空间巨大

核心贡献
FollowBench解决了现有指令遵循评估的根本性问题:
- 多维约束全覆盖:首次系统性地涵盖内容、情境、风格、格式、示例五大约束类型
- 多层级难度递进:创新性地通过逐步添加约束来精确测量模型能力上限
- 过程感知评估:提出约束演化路径提示,让评估模型更准确理解约束要求
- 现实场景导向:基于真实应用需求设计,而非学术化的人工任务
问题背景:指令遵循评估的三大盲点
现有评估的致命缺陷
想象一下,如果我们用考试来比喻AI模型评估:现有的方法就像是只看总分,不看各科成绩。虽然总分不错,但数学、语文、英语哪一科拖了后腿,我们完全不知道。
1. 忽视细粒度约束
现有基准主要关注"回答质量"这个大而化之的概念:
- 帮助性好不好? ✓
- 内容相关吗? ✓
- 逻辑清晰吗? ✓
但却忽略了最关键的问题:模型是否真的遵循了指令中的具体要求?
2. 缺乏难度层次设计
就像健身房只有最重的杠铃,没有渐进式训练:
- 要么是简单到一步就能完成的任务
- 要么是复杂到无从下手的综合性评估
- 缺乏"能举起多重"的精确测量
3. 评估方式过于粗糙
传统评估就像"一刀切"的判分方式:
- 不管推理过程多么精彩,答案错了就是0分
- 无法识别"差一点就对了"和"完全不着边际"的区别
- 错过了很多有价值的诊断信息
核心洞察:约束遵循是指令遵循的本质
真正的指令遵循能力应该是什么样的?让我们看一个例子:
用户:请推荐10本中文书籍,按出版年份排序,用表格格式展示,每本书要包含作者和简短评价。
这个看似简单的指令实际上包含了多个层次的约束:
- 内容约束:必须是书籍,必须是10本
- 语言约束:必须是中文书籍
- 格式约束:必须用表格格式
- 结构约束:必须包含作者和评价
- 排序约束:按出版年份排序
FollowBench的创新就在于:将复杂指令拆解为可测量的细粒度约束,并通过层级递进的方式精确测量模型的能力边界。
技术方法详解
五大约束维度:全方位覆盖现实需求
1. 内容约束:说什么的问题
定义:对响应内容的明确限制和要求
典型场景:
- “推荐10本关于人工智能的书”(数量限制)
- “介绍除了ChatGPT之外的AI模型”(排除性限制)
- “只谈论2020年以后的技术发展”(时间限制)
挑战性:要求模型既要理解限制条件,又要生成符合要求的内容
2. 情境约束:在什么背景下说
定义:通过特定情境引导响应的适切性
典型场景:
- “作为一名刚入职的程序员,如何快速融入团队?”
- “假设你是小学老师,如何向学生解释编程概念?”
- “在公司年会上,如何做一个有趣的技术分享?”
挑战性:需要模型具备角色意识和情境适应能力
3. 风格约束:怎么说的问题
定义:控制输出的语言风格和表达方式
典型场景:
- 正式 vs 非正式:“请您提供相关信息” vs “能告诉我一下吗”
- 技术 vs 通俗:学术论文风格 vs 科普文章风格
- 情感色彩:热情洋溢 vs 客观中性
挑战性:要求模型掌握语言的微妙差异和表达技巧
4. 格式约束:以什么形式呈现
定义:对输出结构和呈现形式的要求
典型场景:
- 表格格式:清晰的行列结构
- JSON格式:结构化数据表示
- 字数限制:精确控制文本长度
- 层级结构:标题、子标题的嵌套关系
挑战性:需要模型同时关注内容质量和结构规范
5. 示例约束:基于模式的学习
定义:通过示例展示期望的输出模式
创新设计:引入"噪声示例"测试模型的鲁棒性
- 正确示例:展示期望的模式
- 噪声示例:故意添加的干扰信息
- 测试目标:模型能否识别真正的模式,忽略干扰
挑战性:考验模型的模式识别和抗干扰能力
多层级机制:精确测量能力边界
设计理念:从简单到复杂的渐进式挑战
传统评估的问题在于"一次性考试":要么全对,要么全错,无法精确定位问题所在。
FollowBench的多层级机制就像阶梯式训练:
Level 1: 推荐10本书
Level 2: 推荐10本中文书
Level 3: 推荐10本中文书,按年份排序
Level 4: 推荐10本中文书,按年份排序,用表格展示
Level 5: 推荐10本中文书,按年份排序,用表格展示,包含评价
能力边界的精确测量
通过这种设计,我们可以精确地说:
- “模型A能稳定遵循3个约束”
- “模型B在第4个约束时开始出错”
- “模型C对格式约束特别敏感”
这就像体能测试中的递增负荷实验,能够精确找到每个人的能力上限。
创新评估方法:约束演化路径提示
传统评估的盲区
以往的评估方法通常是:
“请判断这个回答是否满足指令要求”
但问题是:评估模型如何知道指令中有哪些具体约束?
我们的解决方案:过程透明化
我们向评估模型展示指令的演化过程:
- Level 1约束:推荐书籍
- 新增约束:必须是中文书籍
- 新增约束:按年份排序
- 新增约束:用表格格式
- 新增约束:包含评价
这样,评估模型能够清楚地理解:
- 每个层级新增了什么约束
- 哪些约束被满足了
- 哪些约束被忽略了
三大评估指标:多角度能力测量
1. 硬性满足率(HSR):完美主义的标准
$$\text{HSR} = \frac{1}{m} \sum_{i=1}^{m} \prod_{j=1}^{n} s_{j}^{i}$$
含义:所有约束都必须满足才算成功 类比:就像考试必须每科都及格才能毕业
2. 软性满足率(SSR):局部成功的认可
$$\text{SSR} = \frac{1}{mn} \sum_{i=1}^{m} \sum_{j=1}^{n} s_{j}^{i}$$
含义:计算单个约束的平均满足率 类比:就像看各科的平均分,了解哪些领域表现更好
3. 连续满足级别(CSL):能力上限的精确测量
$$\text{CSL} = \frac{1}{g} \sum_{i=1}^{g} \arg\max_{l} \left( l \times \prod_{n=1}^{l} S_{n}^{i} \right)$$
含义:模型能够连续满足的最高难度级别 类比:就像举重能举起的最大重量
实验结果:揭示模型能力真相
主要发现一:能力上限远低于预期
| 模型 | CSL分数 | 能力描述 |
|---|---|---|
| GPT-4 | ~3.0 | 能稳定遵循3个约束 |
| GPT-3.5 | ~3.0 | 能稳定遵循3个约束 |
| LLaMA2-70B | ~2.5 | 能稳定遵循2-3个约束 |
| 其他开源模型 | ~2.0 | 能稳定遵循2个约束 |
震撼发现:即使是最强的GPT-4,也只能稳定遵循约3个约束条件!
这个结果颠覆了我们对AI能力的认知:
- 在单一任务上表现优异 ≠ 复合约束遵循能力强
- 模型规模大 ≠ 指令遵循能力强
- 需要更多研究来提升这一关键能力
主要发现二:约束类型的难度差异
相对容易的约束:
- 风格约束:大多数模型都能较好地调整语言风格
- 内容约束:基础的内容限制相对容易遵循
特别困难的约束:
- 示例约束:在噪声示例干扰下,模型很难识别真正的模式
- 混合约束:多种约束类型组合时,复杂度急剧上升
- 情境约束:需要深度的上下文理解和角色扮演能力
深层原因分析:
- 训练数据偏差:模型在"干净"数据上训练,缺乏处理噪声的能力
- 注意力分散:多约束并存时,模型难以同时关注所有要求
- 情境理解不足:缺乏真正的"角色意识"和"场景感知"
主要发现三:闭源与开源的显著差距
性能差距惊人:
- GPT-4在所有约束类型上都显著领先
- 开源模型普遍在CSL指标上低1-1.5分
- 差距最大的领域:情境约束、示例约束
可能的原因:
- 数据质量:闭源模型可能使用了更高质量的指令微调数据
- RLHF优化:人类反馈强化学习可能特别有助于约束遵循
- 模型规模:更大的参数量提供了更强的多任务处理能力
主要发现四:解码策略的微妙影响
有趣发现:
- 温度过低(τ=0):输出过于保守,可能错过复杂约束的细节
- 温度过高(τ>0.7):创造性过强,容易偏离约束要求
- 最佳区间(τ=0.3-0.5):在创造性和约束遵循间取得平衡
实践启示:在需要严格遵循约束的场景中,适度的随机性反而有助于模型更好地理解和满足复杂要求。
深度分析:失败模式与改进方向
典型失败案例分析
案例1:格式约束失败
指令:用表格格式列出5个AI公司 模型输出:列表格式而非表格格式 失败原因:对"表格"概念理解模糊,缺乏严格的格式意识
案例2:示例约束失败
指令:根据给定示例(含噪声)完成任务 模型输出:被噪声示例误导,未识别真正模式 失败原因:缺乏模式抽取和干扰过滤能力
案例3:混合约束失败
指令:同时包含内容、格式、风格多种约束 模型输出:满足部分约束,忽略其他约束 失败原因:注意力资源分配不均,无法并行处理多种约束
评估方法验证:88%的人机一致性
我们通过严格的验证实验证明了评估方法的有效性:
| 评估方法 | 与专家一致性 | 说明 |
|---|---|---|
| 我们的方法 | 88% | 使用约束演化路径提示 |
| 移除演化信息 | 79% | 不提供约束演化过程 |
| 传统质量评估 | 67% | 基于整体质量打分 |
| 专家间一致性 | 85% | 人类专家之间的基准 |
关键洞察:约束演化路径的提供是提升评估准确性的关键因素,这验证了我们方法的科学性。
技术创新点
1. 多维度约束分类体系
- 首次系统性地将指令约束分为5大类型
- 每个类型都有明确的定义和评估标准
- 覆盖了现实应用中的主要约束场景
2. 多层级难度递进机制
- 通过逐步添加约束来构建难度梯度
- 能够精确定位模型的能力边界
- 提供了比传统二元评估更细粒度的能力测量
3. 约束演化路径提示
- 创新性地向评估模型展示指令演化过程
- 显著提升了自动评估的准确性
- 为开放式指令的客观评估提供了新思路
4. 多指标综合评估体系
- HSR、SSR、CSL三个指标从不同角度衡量能力
- 既考虑完美性能,也关注局部成功
- 能够提供全面而精确的能力画像
实践启示与未来方向
对模型开发者的启示
- 重视约束遵循训练:不仅要提升回答质量,更要强化约束意识
- 多约束并行处理:开发能够同时处理多种约束的训练方法
- 抗干扰能力训练:在训练数据中引入噪声和干扰信息
对应用开发者的启示
- 分层设计指令:避免在单个指令中添加过多约束
- 约束优先级:明确哪些约束是必须的,哪些是可选的
- 温度参数调优:根据应用场景选择合适的解码策略
对研究者的启示
- 新的评估维度:指令遵循能力是独立于知识和推理的重要能力
- 训练方法创新:需要开发专门针对约束遵循的训练技术
- 评估工具完善:自动化评估方法仍有很大改进空间
局限性与未来展望
当前挑战
- 单轮交互限制:现实应用中的多轮对话约束遵循尚未涉及
- 评估方法依赖:基于LLM的评估仍可能存在偏差
- 语言局限性:主要关注英文和中文,多语言覆盖不足
未来方向
- 多轮对话扩展:研究动态对话中的约束遵循能力
- 评估方法优化:开发更准确、更鲁棒的自动评估技术
- 训练方法改进:基于FollowBench开发针对性的训练策略
- 应用场景拓展:扩展到代码生成、多模态等更多领域
FollowBench为我们揭示了一个重要事实:指令遵循能力是AI走向实用化的关键瓶颈。虽然当前模型在这一能力上仍有很大提升空间,但这也意味着巨大的研究和应用潜力。随着这一能力的不断改进,AI将能够更好地理解和满足人类的复杂需求,真正成为可靠的智能助手。
论文翻译:https://dppemvhuzp.feishu.cn/docx/OJwadgvMVoppYQxEb4VcZVjSnBd?from=from_copylink