论文概览
论文标题:SUPERCORRECT: SUPERVISING AND CORRECTING LANGUAGE MODELS WITH ERROR-DRIVEN INSIGHTS
研究机构:Peking University, National University of Singapore, UC Berkeley, Stanford University
代码仓库:https://github.com/YangLing0818/SuperCorrect-llm
基座模型:Qwen2.5-Math-7B, Meta-Llama3.1-8B, DeepSeek-Math-7B
论文地址:https://arxiv.org/pdf/2410.09008
计算资源:8 × NVIDIA A100-PCIE-40GB GPU
核心贡献
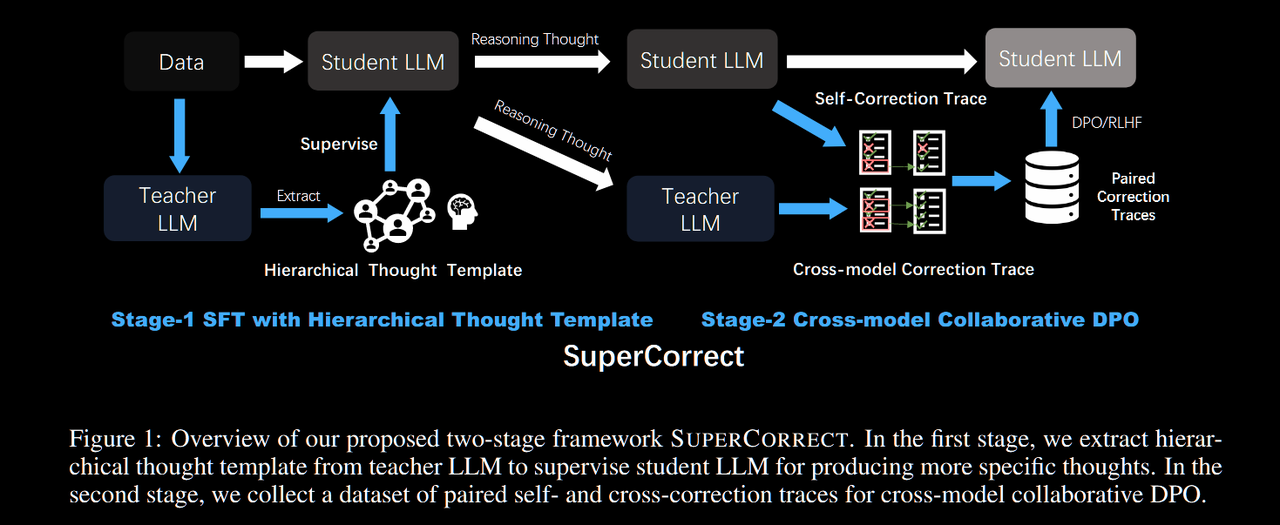
本文提出了 SUPERCORRECT,一个创新的两阶段训练框架,专门用于提升大语言模型的数学推理能力和自我纠错能力:
- 层次化思维微调:设计了包含高级思维和详细解决方案的分层思维模板,指导小型模型生成更细粒度的推理过程
- 跨模型协作DPO:创新性地利用教师模型来定位和纠正学生模型的推理错误,突破思维瓶颈
- SOTA性能:在7B参数模型中实现了新的最佳性能,MATH数据集达到70.2%,GSM8K达到89.5%
- 高质量数据集:构建了包含10万样本的分层思维数据集和1万样本的纠错偏好数据集
问题背景与动机
现有方法的困境
我们都知道,GPT-4、PaLM这样的大型语言模型在推理任务中表现惊艳,但当我们把目光转向更小的模型时,情况就不那么乐观了。像Llama-3-8B、DeepSeekMath-Base这样的模型在面对复杂数学推理时,往往会"力不从心":
- 传统微调的盲点:就像只看考试答案而不关心解题过程,这些方法主要盯着最终结果,却忽略了推理链条中的关键错误
- 自我反思的局限:虽然尝试让模型"自我检讨",但就像人很难发现自己思维的盲区一样,模型也很难独立发现自己推理中的漏洞
- 思维的固化:单个模型容易陷入自己的思维定式,就像我们常说的"当局者迷"
核心洞察:师生协作的智慧
问题的关键在于:如何让小模型具备发现并修正自身推理错误的能力?
这就像学习数学时,有经验的老师能够精准地指出学生解题中的错误所在,并给出正确的指导。SUPERCORRECT 的核心思想正是基于这种师生协作的智慧:让强大的教师模型充当"导师"角色,帮助小模型识别和纠正推理错误。
技术方法详解
第一阶段:层次化思维训练
为什么需要分层思维?
想象一下,当我们解决复杂数学问题时,通常会先形成一个总体的解题思路,然后再逐步展开详细的计算步骤。SUPERCORRECT 的分层思维模板正是模拟了这种自然的思考过程:
- 高级思维:就像解题前的整体规划,为类似问题提供方向性的指导
- 详细解决方案:如同具体的计算步骤,给出每一步的详细推理过程
这种设计让小模型不仅知道"怎么做",更重要的是理解"为什么这样做"。
训练目标
我们的训练目标可以用以下公式表示:
$$\mathcal{L}{sft} = -\mathbb{E}{(x, T_{tea}, s_{tea}) \sim \mathcal{D}{sft}} \left[ \log \pi\theta((T_{tea}, s_{tea}) | P_{stu}, x) \right]$$
简单来说,就是让学生模型学会模仿教师模型的分层思维方式,既要掌握高层次的解题策略,也要理解具体的推理步骤。
第二阶段:跨模型协作纠错
传统DPO的不足
标准的DPO方法虽然有效,但在数学推理中存在一个致命问题:它采用的是"一刀切"的评判方式。就像批改作业时,只要最终答案错了就全盘否定,不管前面的步骤是否正确。
这种做法在复杂推理中特别有害,因为:
- 错误往往只出现在某个关键步骤上
- 可能会误杀很多正确的推理过程
- 模型很难从粗糙的反馈中学到精准的纠错技巧
我们的解决方案:精准的错误定位与纠正
SUPERCORRECT 的跨模型DPO就像一位细心的老师,会:
精确找出错误:教师模型 $\pi_{tea}$ 会仔细检查学生模型 $\pi_{ref}$ 的每一步推理,定位到第一个出错的步骤 $k$
提供对比示例:
- 正面教材:教师模型展示如何正确分析和纠正这个错误 $(a_k^+, c_k^+)$
- 反面教材:保留学生模型的错误纠正尝试 $(a_k^-, c_k^-)$
精细化训练:通过对比学习,让学生模型明白"什么是好的纠错"vs"什么是差的纠错"
这个过程的数学表达为: $$\mathcal{L}{Cross-DPO} = -\mathbb{E} \left[ \log \sigma \left( \beta \log \frac{\pi\theta(a_k^+, c_k^+ | context)}{\pi_{ref}(a_k^+, c_k^+ | context)} - \beta \log \frac{\pi_\theta(a_k^-, c_k^- | context)}{\pi_{ref}(a_k^-, c_k^- | context)} \right) \right]$$
质量保证:多重检验机制
为了确保教师模型的指导质量,我们还引入了"检查器"机制,就像有一位督学在旁边监督教学质量:
- 自动检验纠正轨迹的准确性
- 发现问题时及时要求重新修订
- 最多进行三轮检查,确保质量过关
实验结果与分析
令人瞩目的性能提升
让数据来说话!在7B参数规模的模型中,SUPERCORRECT 刷新了性能记录:
| 模型 | MATH | GSM8K |
|---|---|---|
| DeepSeekMath-7B | 62.4% | 84.2% |
| Qwen2.5-Math-7B | 55.1% | 83.2% |
| SUPERCORRECT-Qwen-7B | 70.2% | 89.5% |
| SUPERCORRECT-DeepSeek-7B | 70.2% | 89.5% |
这些数字背后的意义不容小觑:
- 相比DeepSeekMath-7B:在MATH上提升了7.8%,GSM8K上提升了5.3%
- 相比Qwen2.5-Math-7B:在MATH上提升了15.1%,GSM8K上提升了6.3%
自我纠错:从"越改越错"到"越改越对"
有趣的是,当我们让模型尝试自我纠错时,发现了一个有趣的现象:
- 其他模型:要么纠错能力有限,要么甚至出现"越改越错"的尴尬情况
- SUPERCORRECT:能够稳定地将准确率再提升5~6%,真正做到了"闻过则喜,知错能改"
这种差异的根源在于:SUPERCORRECT通过师生协作学会了如何精准定位错误并进行有效纠正,而不是盲目的"瞎改"。
消融实验:每个组件都很重要
| 方法 | MATH准确率 |
|---|---|
| 传统SFT | 65.2% |
| HSFT | 70.2% |
| HSFT + Reflexion | 63.2% |
| HSFT + Cross-DPO | 70.2% |
消融实验告诉我们:
- 层次化思维的威力:仅仅改进思维模板就带来了5%的提升
- 协作胜过独立:跨模型DPO比传统的自我反思方法(Reflexion)效果更佳
突破思维瓶颈:让"偏科生"变成"全才"

MATH数据集涵盖了7个不同的数学领域,就像学生的不同科目。有趣的是:
- 传统模型:往往在某些领域表现不错,但在其他领域就"力不从心",像是严重的"偏科生"
- SUPERCORRECT:在所有领域都实现了提升,特别是在原本困难的领域进步更为显著
这说明我们的方法不只是简单的性能提升,而是真正帮助模型突破了原有的思维局限。
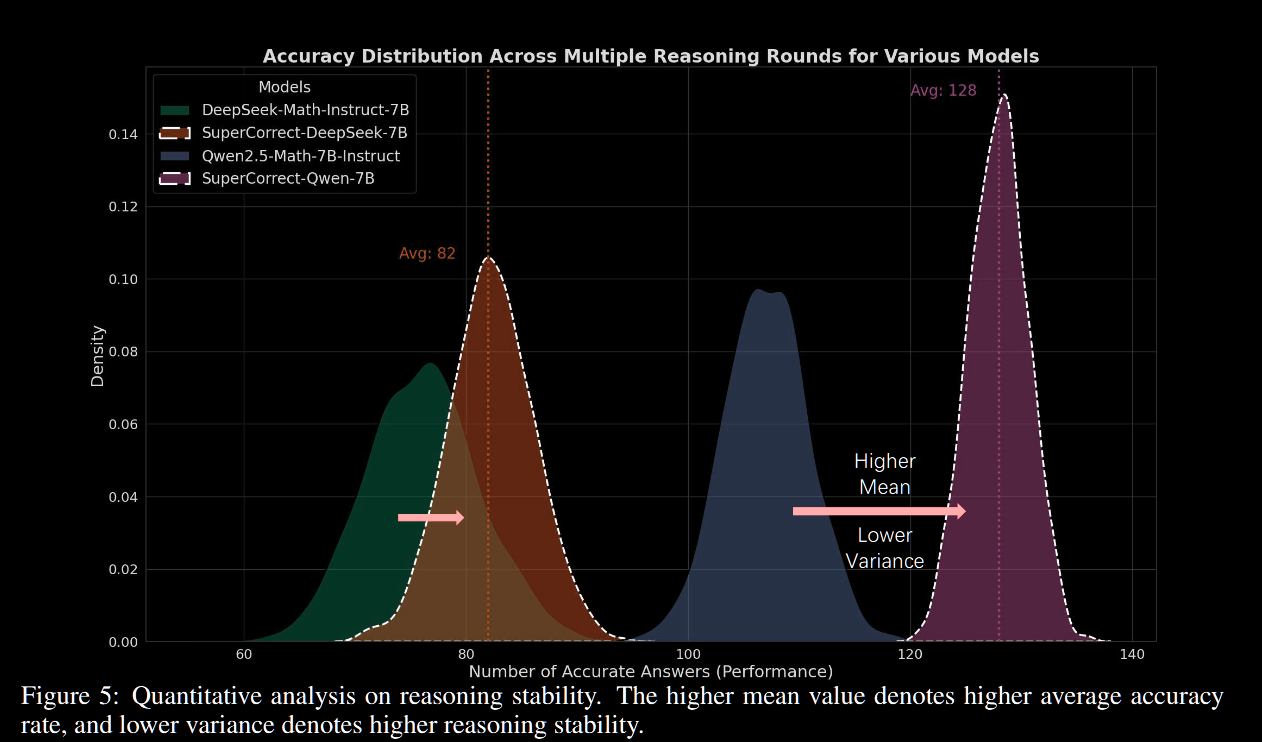
推理稳定性:告别"忽好忽坏"
我们对300个最高难度问题进行了256次重复测试(就像让学生做256次同样的考试),发现:
- 准确率更高:平均表现显著优于基础模型
- 波动更小:推理结果更加稳定,不再出现"今天状态好,明天就拉胯"的情况
定性分析案例
层次化思维的威力:从困惑到清晰
让我们通过一个具体例子来看看层次化思维是如何发挥作用的:
问题:某个关于集合的数学问题,涉及空集的理解
| 方法 | 表现 | 分析 |
|---|---|---|
| CoT提示 | ❌ 错误 | 对"空集"概念理解有误,没意识到512个集合已经包含了空集 |
| 层次化思维 | ❌ 错误 | 虽然理解了空集包含在512个集合中,但没能准确把握题目要求 |
| SUPERCORRECT | ✅ 正确 | 不仅理解了空集概念,还准确抓住了题目的关键要求 |
这个例子很好地展示了层次化思维的价值:它不仅帮助模型理解概念,更重要的是帮助模型理解"题目真正在问什么"。
纠错能力大比拼:Step-DPO vs Cross-model DPO
我们也对比了其他的纠错方法:
Step-DPO的表现:
- ✅ 能够找到错误的推理步骤
- ❌ 但纠正得不够彻底
- ❌ 修正后的结果还是不够准确
我们的Cross-model DPO:
- ✅ 精确定位错误步骤
- ✅ 提供准确有效的修正
- ✅ 彻底解决原本无法处理的问题
就像医生看病一样,找到病因只是第一步,关键是要能"对症下药",彻底治愈。
数据集构建:质量是王道
我们的"教材"组成
好的方法需要好的数据支撑,我们精心构建了两套高质量数据集:
层次化思维数据集(10万样本):
- 涵盖各类数学问题
- 包含高级思维模板(解题策略)
- 包含详细解决方案(具体步骤)
纠错偏好数据集(1万样本):
- 收集错误推理步骤
- 对比教师模型的正确纠正(正面教材)
- 对比学生模型的错误尝试(反面教材)
质量控制:严格把关每一份"教材"
我们引入了检查器机制来确保数据质量,效果显著:
| 教师模型 | 数据集 | 直接生成质量 | 经检查器优化后 | 提升幅度 |
|---|---|---|---|---|
| o1-mini | MATH | 85.2% | 92.8% | +7.6% |
| GPT-4o | GSM8K | 78.9% | 87.3% | +8.4% |
就像出版社的编辑会反复校对书稿一样,我们的检查器确保了每份训练材料都是高质量的。
局限性与未来展望
当前的挑战
任何方法都不是完美的,SUPERCORRECT 也有需要进一步改进的地方:
- 计算资源要求较高:需要强大的教师模型参与训练,就像请名师辅导一样,成本相对较高
- 专门针对数学推理:目前主要在数学领域验证,其他推理任务的适用性还需要进一步探索
- 模型规模限制:实验主要集中在7B规模,更大模型的效果还待验证
未来的发展方向
尽管有这些挑战,但前景依然令人兴奋:
- 规模扩展:验证方法在更大规模模型(如70B、175B)上的效果
- 领域拓展:将师生协作的思想推广到科学推理、逻辑推理等其他领域
- 效率优化:探索如何减少对教师模型的依赖,降低训练成本
SUPERCORRECT 为我们展示了师生协作在AI训练中的巨大潜力。就像人类教育中师生互动的重要性一样,AI模型之间的协作可能会成为未来提升模型能力的重要方向。
完整论文翻译:https://dppemvhuzp.feishu.cn/docx/Bfmjd2jziopDVwxgEZ5ciOfKnWe?from=from_copylink