在本文中,如图 1 所示,我们介绍了 LiDARLLM,这是一种利用 LLM 的推理能力全面理解户外 3D 场景的新方法。LiDAR-LLM 架构包括 3D LiDAR 编码器、中间对齐变换器和 LLM,例如 LLaMA [42]。LiDARLLM 的关键见解在于通过解释性语言建模重新定义 3D 场景认知问题。然而,引入 LLM 来感知户外 3D 场景面临两个挑战:(1)与丰富的图像文本配对数据 [9, 40, 41] 相比,3D LiDAR-文本配对数据极其稀少,并且缺乏易于获取的多模态模型(例如 CLIP [39])。(2)3D LiDAR 数据包含各种对象及其之间复杂的几何关系。以户外自动驾驶为例, 其中自主车辆被各种移动和静止的物体所包围,这些物体相互遮挡和影响。
为了应对这些挑战,对于 LiDAR-LLM,我们引入了三阶段训练策略并生成相关数据集,逐步将 3D 表示转移到文本特征空间并释放 LLM 对 3D 场景的推理能力。具体来说,在第一阶段,我们使用 MLLM [28, 50] 和 GPT4 [34] 在 nuScenes 数据集 [7] 内进行多视图图像和语言之间的通信,其中每个场景都伴随着成对的 3D LiDAR 数据。通过这种方式,我们生成了一个包含 420K liDAR-文本对的数据集,并将 3D LiDAR 特征与 LLM 的词嵌入进行跨模态对齐。在第二阶段,由于感知构成了 3D 场景理解的基础,我们将 3D 边界框合并到问答文本中并生成一个 280K LiDAR 基础数据集.
这增强了 LiDAR-LLM 对物体位置和关系的敏感性。在最后阶段,我们在高级指令数据集 [15, 38] 上对我们的模型进行了有效的微调,全面扩展了其 3D 下游任务的能力。为了更有效地弥合 3D LiDAR 和文本之间的模态差距,我们设计了一个 View-Aware Transformer (VAT),将 3D LiDAR 编码器与 LLM 连接起来,将六个视图位置嵌入注入 3D 特征中。结合三阶段训练策略,VAT 增强了 LLM 对视觉特征空间方向的理解。总之,我们的贡献如下:
我们提出了 LiDAR-LLM,它以 3D LiDAR 数据和语言提示作为输入,利用 LLM 的推理能力来理解户外 3D 场景。 LiDAR-LLM 可以执行 3D 字幕、3D 基础、3D 问答等任务。 • 我们引入了一种三阶段训练策略,用于逐步将 3D 表示转移到文本特征空间,其中包括跨模态对齐、感知和高级指令。同时,我们收集了一组 LiDAR-文本配对数据集,包括 420K 3D 字幕和 280K 3D 基础数据,这些数据集即将发布。 • 我们专门设计了一个 View-Aware Transformer (VAT),将 3D LiDAR 编码器与 LLM 连接起来,缩小了 3D LiDAR 和文本之间的模态差距,并增强了 LLM 对视觉特征空间方向的理解。 • 在我们提出的 LiDAR-text 数据集中,LiDAR-LLM 表现出色,在 3D 字幕数据集上获得了 40.9 BLEU-1 分数,并在 3D 接地数据集上获得了 63.1% 的分类准确率和 14.3% 的 BEV mIoU。
广泛的语言模型,例如 LLaMA [42] 和 GPT-3 [19],利用其强大的推理和泛化能力,展示了处理各种语言任务的能力。在这些成就的基础上,引入了 2D 多模态大型语言模型 (2D MLLM) [17、28、50] 来连接 RGB 视觉图像和文本。这些模型利用大型语言模型 (LLM) [42] 的功能,并通过对 2D 输入进行调节,旨在解决 2D 下游任务,例如视觉问答 [3] 和字幕 [2]。 代表性模型 BLIP [28] 使用从大规模嘈杂图像文本对引导的数据集对多模态编码器-解码器模型混合进行预训练。它注入不同的合成字幕并删除嘈杂字幕,以实现统一的视觉语言理解和生成。同时,VisionLLM [44] 将以视觉为中心的任务与语言任务结合起来,允许通过语言指令进行灵活的定义和管理。此外,3D 多模态大型语言模型 (3D MLLM) [22、24、45、46] 的引入旨在扩大从 LLM 获得的知识、推理和对话能力的范围,以涵盖 3D 模态。例如,几个项目利用 GPT-3 [19] 或 LLaMA [42] 来提高基于语言的 3D 空间几何理解,如 PointCLIP V2 [54] 和 ViewRefer [21] 等作品所展示的那样。他们专注于具有单个对象或室内场景的 3D 点云。与这些方法相比,我们是第一个利用 LLM 的推理能力来理解户外 3D 场景并完成字幕、3D 基础和 3D 问答等任务的人。 3D LiDAR 点云数据带来的独特挑战包括缺乏 LiDAR-文本配对数据以及包含各种对象和关系,这给多模态对齐和推理带来了困难。
3D 点云和自然语言的结合具有多种应用,最近引起了越来越多的关注 [1, 10, 11, 18, 23, 26]。具体来说,需要 3D 字幕 [11, 13] 来描述 3D 场景中的特定对象。3D 视觉基础 [10, 48] 专注于生成文本表达所指对象的位置。同时,在 3D 视觉问答 [5] 的背景下,模型需要根据 3D 场景的视觉内容回答语言问题。然而,上述任务的 3D 方法旨在解决单个任务特定的挑战,而没有探索它们的共性并提供统一的解决方案。此外,这些方法是针对室内点云任务量身定制的,可能无法直接转移到室外 LiDAR,因为 LiDAR 在几何关系上更稀疏、更多样化。为了解决这一问题,我们提出了 LiDAR-LLM,一种面向 LiDAR 的方法,以统一 执行户外场景的 3D 任务。
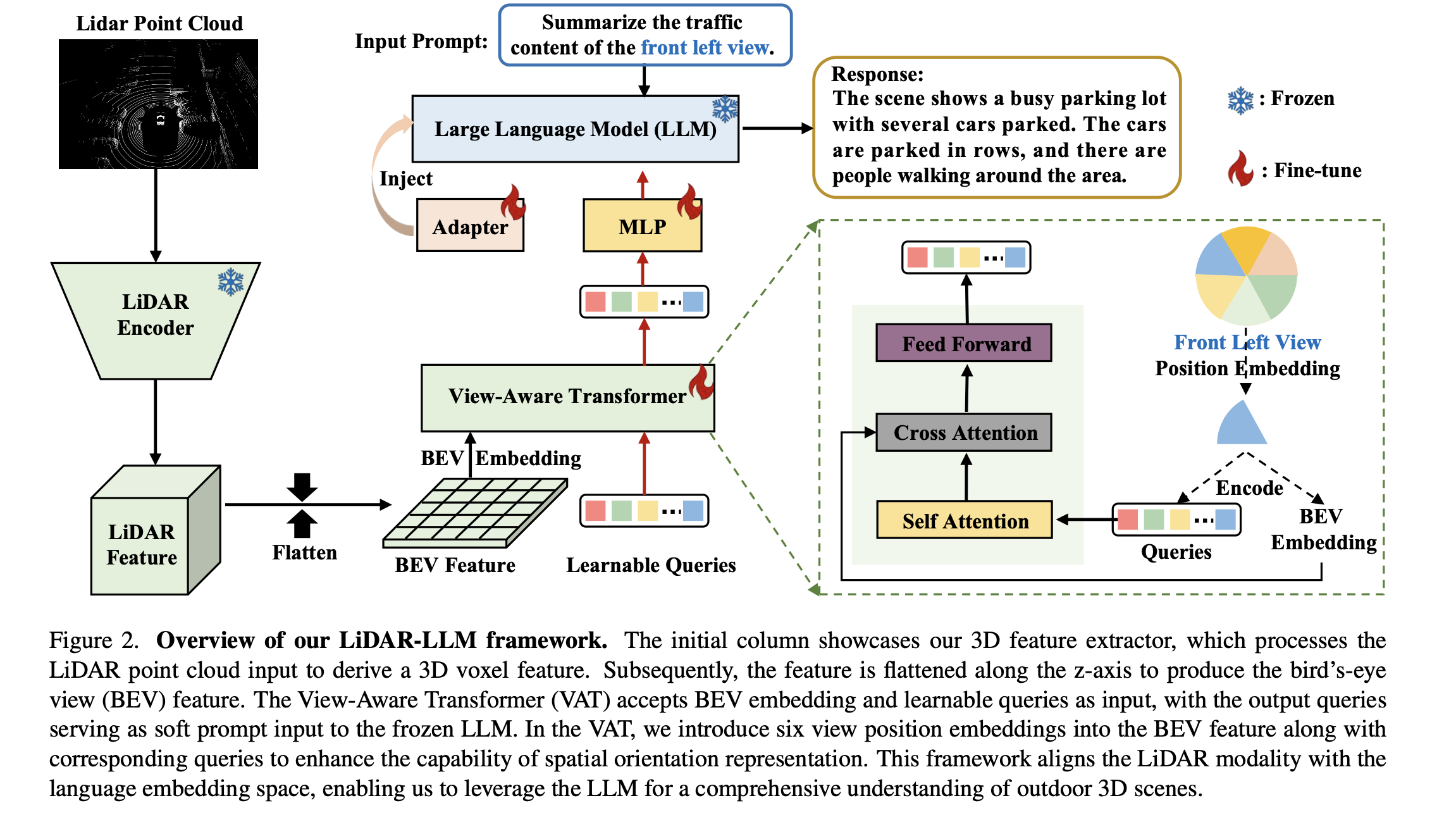
LiDAR-LLM 的总体框架如图 2 所示。其核心概念涉及将高度稀疏和复杂的几何 LiDAR 数据转换为大型语言模型 (LLM) 可以理解的表示空间。我们提出的视图感知变换器 (VAT) 促进了这种转换,它结合了视图位置嵌入来增强 LLM 的空间方向理解。因此,它可以全面解释户外 3D 场景中的复杂细节。然而,将 LLM 集成到理解户外 3D 场景中面临两个挑战:(1) 与大量可用的图像文本配对数据不同,3D LiDAR 文本配对数据极其稀缺;(2) 3D LiDAR 数据涉及各种对象及其之间复杂的几何关系。因此,我们实施了三阶段训练策略并生成 LiDAR-文本配对训练数据,以协作地将 3D 表示与 LLM 的特征空间对齐。通过此过程,LiDAR-LLM 跨模态执行各种任务,并在场景和实例级别处理复杂的跨模态场景。它释放了 LLM 在 3D LiDAR 数据上的常识推理和定位能力。
给定一个 LiDAR 输入 L ∈ R n×3 ,其中 n 是点数,使用 VoxelNet [52] 提取其 3D 体素特征。随后,考虑到计算成本,我们沿 z 轴展平该特征以生成鸟瞰图 (BEV) 特征。同时,对于最多有 m 个字符的文本输入 T,使用 LLaMA [42] 提取文本特征。利用 BEV 特征 Fv ∈ R c×h×w 以及文本特征 Ft ∈ R m×d (其中 d 是特征的维度),我们的目标是通过我们提出的 View-Aware Transformer (VAT) 将这些 LiDAR BEV 特征投影到预先训练的 LLaMA 的词嵌入空间中。这种对齐对于进行多模态理解和在 3D 下游任务中生成准确答案至关重要。在训练过程中,我们仅对 LLaMA 和 VAT 模块中注入的适配器 [25] 进行微调,同时冻结主要参数。这旨在保留现有模块强大的特征提取和推理能力,并进一步使模型具备理解 3D LiDAR 场景的能力。
VAT 设计。在图 2 的右侧部分,VAT 的输入包括一组 K 个可学习的查询嵌入,其中 K 设置为 576,以方便投影到 LLM 的字嵌入空间中。这些查询通过交叉注意机制与 BEV 特征交互。VAT 产生一个输出,包含 K 个编码的视觉向量,每个查询嵌入一个。然后,这些向量通过多层感知器 (MLP) 进行处理,随后输入到冻结的 LLM 中。然而,户外 LiDAR 数据,例如 nuScenes [7],需要全面了解不同物体与自我汽车之间的方向关系。它包含了物体之间错综复杂的关系。因此,我们为 BEV 特征引入了视图位置嵌入,目的是提升模型学习方向和几何关系的能力。具体来说,我们首先构造具有零初始参数的视图位置嵌入 Vp ∈ R c×6。然后,我们根据六个视图拆分 BEV 特征,包括正面、右前、左前、背面、右后和左后视图。在训练期间,当处理与特定视图相关的问题时,我们将相应的位置嵌入注入到 BEV 特征和查询中。例如,在训练与左前视图相关的字幕样本时,我们仅将左前位置嵌入 Vp ∈ R c×1 注入到 BEV 特征和查询的左前视图部分。如果训练样本涉及有关整个全景场景的问题,我们在训练期间注入所有六个视图位置嵌入。
在本节中,我们将展示如何赋予 LLM 理解 3D LiDAR 数据和统一完成大量 3D 任务的能力。我们引入了一种三阶段训练策略并生成相关数据集,逐步将 3D 表示转移到文本特征空间。三个阶段包含跨模态对齐、感知和高级指令。 跨模态对齐(3D 字幕):为了有效解决丰富的 3D 下游任务,该模型需要彻底了解 LiDAR 场景。场景字幕是一种逻辑方法,通过将整个 3D 场景集成到 LLM 中,使模型能够捕获 LiDAR 数据中的基本信息和细节。
然而,由于缺乏用于字幕训练的直接 LiDAR 和文本描述对,我们利用 nuScenes [7] 中与 LiDAR 数据对齐的现有多视图图像来创建文本描述。利用强大的现成 2D 多模态 LLM (MLLM) [28, 50],我们为每个视图生成字幕,创建与 LiDAR 场景相对应的文本描述。然而,LiDAR 数据和 2D 多视图的字幕并不完全一致,因为 2D MLLM 可能会为 2D 图像提供与天气或颜色相关的描述,而这些描述不适用于 LiDAR 数据。为了解决这种不一致,我们进一步使用 GPT-4 [34] 来筛选出与 LiDAR 数据更相关且更合适的字幕。
利用收集到的 LiDAR-caption 对,我们的目标是使 LLaMA 能够根据 LiDAR 输入生成描述性文本。我们观察到,由于 LiDAR 数据的几何结构复杂,其文本字幕往往过于详细和冗长。联合学习整体字幕可能会导致 LLM 推理中的纠缠。为了缓解这种情况,我们最初训练模型为单个视图添加字幕以降低复杂性。使用交叉熵损失,输出字幕由相应视图的真实答案监督。在使模型获得单个视图的字幕技能后,后续步骤涉及指示模型了解整个全景场景并生成全局描述。通过这样做,我们将 3D 特征表示与 LLM 的文本特征空间对齐,使模型能够理解 LiDAR 数据中的上下文。
感知:在为模型配备全局场景理解后,此阶段专注于赋予模型实例级感知能力,因为它们构成了规划等高级教学任务的基础。为了实现这一点,我们采用了以对象为中心的学习策略,确保模型能够识别各种对象细节,例如数量、定位和空间关系。该模型学习单个 3D 对象的表示与与对象相关的 LLM 的相应文本嵌入之间的对齐。
为此,我们设计了两个任务,即视觉接地和接地字幕。首先将对象表示为离散标记序列,其中提取每个对象的标签和边界框。给定一个带有注释的 3D 对象,使用预训练 LLM 的标记器将类别名称和位置编码为词嵌入。与之前的室内 3D MLLM [45] 不同,不需要单独从点云中提取每个对象;相反,我们在整个 3D 场景中实现对象感知。对于视觉接地,该模型学习根据 LiDAR 输入和指令生成指定区域位置 (x1、y1、z1、x2、y2、z2、θ) 的位置标记,其中 θ 是框角度。接地字幕任务被定位为视觉接地的反向对应项。该模型通过利用输入的 LiDAR 数据和带有位置信息的文本来训练生成描述性文本。这两项任务的输出都通过交叉熵损失进行监督。指令的表述如图 3 所示。此对齐过程旨在将 3D 视觉对象嵌入与文本嵌入空间对齐,从而释放 LLM 的 3D 感知能力。
高级指令:在此阶段,我们全面了解了 LiDAR 场景并为模型配备了基本的 3D 感知功能,然后利用高级指令数据集(例如 nuScenes-QA [38])进一步增强模型在 3D 空间中的推理能力。通过使用此数据集对 LiDAR-LLM 进行微调,我们不仅提高了其理解各种指令的能力,还使其能够生成既有创意又符合语境的响应。此外,这一改进过程使 LiDAR-LLM 能够进行复杂的空间推理并将外部知识整合到其生成的响应中。这些任务也通过交叉熵损失进行监督,确保模型的输出与所需的高级指令有效对齐。同时,我们还在 nuScenes 数据集 [7] 上探索了 LiDAR-LLM 的自动驾驶规划能力。我们不生成任何规划 QA 数据,而是直接利用训练好的模型来推断与规划相关的问题。我们发现,通过我们提出的三阶段训练策略,LiDAR-LLM 可以开发初步的规划能力,如图 3 所示。结果还表明,我们的训练流程可以刺激模型在 3D LiDAR 数据中的推理能力。
LiDAR-LLM 与各种任务和数据集进行联合微调,使其具备了一套多功能的技能,能够熟练地处理复杂的跨模态场景中的各种任务。在微调阶段,我们对由我们生成的 700K LiDAR-文本对和 460K 公开可用的数据集 [38] 组成的数据集进行微调。在整个训练过程中,上述任务都是循序渐进地进行系统训练的。在推理过程中,我们的输入仍然由 LiDAR 和问题文本组成。我们可以灵活地单独推断每个问题或连续推断多个问题。
总之,我们的论文代表了一项开创性的努力,旨在释放 LLM 的推理能力来理解户外 LiDAR 数据。我们提出的 LiDAR-LLM 将 3D 户外场景理解的复杂挑战重新表述为语言建模问题。为了训练 LiDAR-LLM,我们生成了一套全面的 LiDARtext 配对数据集,包括 420K 3D 字幕和 280K 3D 基础数据。然后,我们引入了一种三阶段训练策略,涉及跨模态对齐、感知和高级指令,将 LiDAR 模态与 LLM 的语言嵌入空间对齐。我们的架构创新引入了 View-Aware Transformer (VAT) 来将 3D 编码器与 LLM 连接起来。这种设计有效地弥合了模态差距,增强了 LLM 对 LiDAR 特征中空间方向的理解。通过对我们生成的数据集和开源数据集进行大量实验,我们的 LiDAR-LLM 在各种任务中表现出色,包括 3D 字幕、3D 接地、3D 问答和自动驾驶规划。在未来的工作中,我们将探索 MLLM 的持续迁移学习 [20, 32, 47] 和轻量级操作 [8, 29],从而可以在边缘设备上部署 MLLM。