
图 1 | 我们展示了 SpatialVLM,这是一种数据合成和预训练机制,用于增强 VLM 的空间推理能力。我们证明,在我们的合成数据上训练的 VLM 表现出强大的空间推理能力,并且可以从 2D 输入图像生成度量距离估计,从而解决了当前最先进的 VLM(如 GPT-4V)的盲点。(∗ GPT-4V 于 2023 年 11 月访问)。
abstract
理解和推理空间关系是视觉问答 (VQA) 和机器人技术的基本能力。虽然视觉语言模型 (VLM) 在某些 VQA 基准测试中表现出色,但它们仍然缺乏 3D 空间推理能力,例如识别物理对象的定量关系,如距离或大小差异。我们假设 VLM 有限的空间推理能力是由于训练数据中缺乏 3D 空间知识,并旨在通过使用互联网规模的空间推理数据训练 VLM 来解决此问题。为此,我们提出了一个系统来促进这种方法。我们首先开发了一个自动 3D 空间 VQA 数据生成框架,该框架可在 1000 万张真实世界图像上扩展到 20 亿个 VQA 示例。然后,我们研究了训练配方中的各种因素,包括数据质量、训练管道和 VLM 架构。我们的工作以度量空间中的第一个互联网规模 3D 空间推理数据集为特色。通过在这些数据上训练 VLM,我们显著增强了其在定性和定量空间 VQA 方面的能力。最后,我们证明,由于其定量估计能力,此 VLM 解锁了思路链空间推理和机器人技术中的新型下游应用。
1 introduction
近年来,视觉语言模型 (VLM) 在各种任务中取得了重大进展,包括图像字幕、视觉问答 (VQA)、具身规划、动作识别等 [2、18、25、33]。虽然 VLM 是适用于各种任务的强大通用模型,但大多数最先进的 VLM 仍然难以进行空间推理,即需要理解物体在 3D 空间中的位置或它们之间的空间关系的任务。空间推理能力本身很有用,但也适用于机器人或 AR 等下游应用。例如,具有空间推理能力的 VLM 可以用作更好的通用奖励注释器 [54] 和成功检测器 [19]。
对 VLM 等基础模型的探索往往受到人类能力的启发。人类通过具体体验和进化发展,拥有天生的空间推理能力。我们可以轻松地确定空间关系,例如物体相对于彼此的定位或估计距离和大小,而无需复杂的思路或心理计算。这种直接空间推理任务的自然能力与 VLM 当前的局限性形成了鲜明对比,因此阻止了它们完成需要多步空间推理的现实世界任务。这一差距使我们提出了一个引人注目的研究问题:我们能否赋予 VLM 类似于人类的空间推理能力?
因此,我们假设,当前 VLM 的空间推理能力有限并不是由于其架构的根本限制,而是由于训练此类模型的规模上可用的通用数据集的限制。例如,许多 VLM [12, 18, 44] 是在互联网规模的数据集上进行训练的,这些数据集以图像-标题对 [13] 为特征,其中包含有限的空间信息。这部分是由于难以获得空间信息丰富的具体数据或用于 3D 感知查询的高质量人工注释。
自动数据生成和增强技术是解决数据限制问题的一种方法 [38, 53, 56, 66]。然而,大多数以前的数据生成工作都侧重于渲染具有真实语义注释的照片级图像,但忽略了对象和 3D 关系的丰富性。相比之下,我们专注于直接从现实世界数据中提取空间信息,以捕捉真实 3D 世界的多样性和复杂性。
**我们的主要见解是,现成的视觉模型的最新进展可以从 2D 图像自动生成丰富的 3D 空间注释。**为此,我们提出了一个名为 SpatialVLM 的系统,该系统能够生成和训练 VLM,以增强其空间推理能力。具体来说,通过结合 1) 开放词汇检测、2) 度量深度估计、3) 语义分割和 4) 以对象为中心的字幕模型,我们可以大规模地对现实世界数据进行密集注释。SpatialVLM 将视觉模型生成的数据转换为一种格式,可用于在字幕、VQA 和空间推理数据的混合上训练 VLM。
通过实验,我们发现经过训练的 VLM 展现出许多理想的功能。首先,它回答定性空间问题的能力大大增强。其次,尽管训练数据嘈杂,它仍能可靠地进行定量估计。这种能力不仅让它掌握了关于物体大小的常识性知识,而且使它成为重新排列任务的开放词汇奖励注释器。第三,我们发现这种空间视觉语言模型得益于其自然语言界面,当与强大的大型语言模型相结合时,可以执行空间思维链来解决复杂的空间推理任务。
我们的主要贡献是: • 我们赋予 VLM 定量空间推理能力,这是人类的基本能力。 • 我们设计了一个框架,基于互联网规模的真实世界图像自动标记 3D 空间推理 VQA 数据。 • 我们研究各种训练方法:数据质量、训练管道、冻结/解冻视觉编码器等,并研究它们如何影响学习质量。 • 我们展示了 SpatialVLM 在复杂推理和机器人技术方面的新功能,这些功能由引入的任务和方法解锁。
2相关工作:
学习空间推理。传统上,空间距离估计是更广泛任务的一部分,例如 SLAM [8, 21] 或深度估计 [24]。在将这些空间概念应用于推理时,先前的研究通常侧重于显式空间场景记忆 [27, 28] 或空间场景图 [31, 32, 62, 63]。场景图允许基于它们编码的空间结构进行可解释、结构化、统计关系学习。要回答 VQA 格式的空间问题,它们必须将其明确地作为所述场景图上的寻路问题来处理。另一方面,VLM 是在来自视觉语言数据集的大量松散结构信息上进行预训练的。与场景图不同,空间理解是隐式编码的。我们可以通过辅助任务 [36, 47] 将深度和 3D 结构注入权重中,从而捕获关系信息。在我们的工作中,我们直接在 VLM 中解决空间关系问题,而无需显式底层场景图。除了从定性角度理解相对关系外,我们还探索估计场景中物体之间的显式度量距离关系。
视觉语言模型的基础。大型语言模型 (LLM) 在互联网规模的数据上进行训练,使其成为有效的常识推理器。然而,LLM(以及扩展的 VLM)可能缺乏在社交推理 [42]、物理推理 [26]、物理推理 [46]、具身任务 [1, 34, 58] 和空间推理任务 [44, 55] 中表现良好的必要基础。虽然具有交互式世界体验的语言模型显示出基础改进 [67, 70],但引入大型视觉模型(如 Flamingo [2]、PaLI [12] 或 PaLM-E [18])已使性能飞跃。这些基于视觉的模型已用于多个下游任务,例如机器人成功检测 [18、20、57、68]、动作预测 [7、59] 和奖励预测 [16、23、48、50]。在这项工作中,我们通过在生成的 VQA 数据集上微调 VLM 来解决空间推理问题。通过直接微调此任务上的 VLM,我们继承了底层 VLM 的通用性和推理能力,并展示了这种方法如何能够完成奖励生成等任务。
视觉语言数据集中的空间信息。许多先前的研究都集中在对 VLM 进行基准测试 [61, 69],考虑 VQA 等任务(例如 VQAv2 [29]、OK-VQA [49]、COCO [43] 或 Visual Genome [39])。其他人则专注于细粒度场景理解,例如语义分割 [5, 37]、对象检测 [11] 或对象识别 [15, 60]。其他人则专门将空间推理作为一项任务,回答有关真实 [44, 55] 或模拟 [35] 场景中对象空间关系(例如,上、下、左、右)的问题。该领域的真实数据可能受到人类标记者生成的数量的限制,而合成数据的表达能力本质上是有界限的。在这项工作中,我们考虑如何自动生成真实数据,并关注不仅仅是空间关系的问题,还有度量空间距离的问题,这可以直接应用于许多下游任务。

3 SpatialVLM
为了使 VLM 具备定性和定量的空间推理能力,我们建议生成一个大规模的空间 VQA 数据集,用于训练 VLM。具体来说,我们设计了一个全面的数据生成框架,该框架首先利用现成的计算机视觉模型,包括开放词汇检测、度量深度估计、语义分割和以对象为中心的字幕模型来提取以对象为中心的上下文,然后采用基于模板的方法生成大量质量合理的空间 VQA 数据。我们使用生成的数据集训练我们的 SpatialVLM,以学习直接的空间推理能力,然后我们可以将其与 LLM 中嵌入的高级常识推理相结合,以解锁思路链空间推理。
3.1. Spatial Grounding from 2D Images
我们假设,当今 VLM 缺乏空间推理能力的原因不是其架构,而是缺乏空间推理训练数据。基于这一见解,我们设计了一个生成包含空间推理问题的 VQA 数据的管道。该管道总结在图 2 中,详细描述如下。
语义过滤:虽然互联网规模的图像字幕数据集已广泛应用于 VLM 训练 [12],但这些数据集中的许多图像不适合合成空间推理 QA,因为它们要么由单个对象组成,要么没有场景背景(例如购物网站上的产品图片或计算机屏幕的屏幕截图)。因此,作为数据合成流程的第一步,我们采用基于 CLIP 的开放词汇分类模型对所有图像进行分类,并排除那些不适合的图像。
从 2D 图像中提取以对象为中心的上下文:为了从 2D 图像中提取以对象为中心的空间上下文,我们利用一系列现成的专家模型,包括区域提议、区域字幕 [4] 和语义分割 [41] 模块来提取以对象为中心的信息。通过这一步,我们获得了由像素簇组成的以对象为中心的实体以及开放词汇字幕描述。
将 2D 上下文提升到 3D 上下文:使用对象检测和边界框定位 [40] 生成的传统空间 VQA 数据集仅限于 2D 图像平面(缺乏深度或高度上下文)和像素级推理(缺乏公制尺度大小和距离上下文)。我们执行深度估计 [6] 以将单目 2D 像素提升到公制尺度 3D 点云。我们进一步将点云的相机坐标系规范化为大地坐标系,这是通过水平表面(例如“地板”、“桌面”)分割 [9] 和帧传输完成的。据我们所知,我们是第一个将互联网规模的图像提升到以对象为中心的 3D 点云并使用它来合成嵌入 3D 空间推理监督的 VQA 数据的人。
歧义解决:有时,一幅图像中会出现多个相似类别的对象,这会导致其标题标签出现歧义。例如,同一个标题标签“蛋糕”可以指代同一幅图像中的多个不同蛋糕。因此,在询问有关这些对象的问题之前,我们需要确保引用表达式没有歧义。我们做出了两个关键的设计选择,这些选择已经通过经验验证,可以有效应对这一挑战:
• 我们刻意选择避免使用常见的对象检测器,因为它们往往会产生固定且粗略的类别,例如“蛋糕”,并采用 FlexCap [4],这是一种用户可配置的以对象为中心的字幕方法。在实践中,对于每个对象,我们可以抽取一个长度在 1-6 个字之间的可变随机字幕。因此,我们的对象注释非常细粒度,例如“形状像房子的蛋糕”和“塑料容器中的纸杯蛋糕” • 我们设计了一种面向语义的后处理算法,通过增强或拒绝对象标题来进一步消除歧义。该算法的详细信息如附录 A.2 所示。
3.2. Large-Scale Spatial Reasoning VQA Datase
正如第 3 节所述,我们的研究重点是通过使用合成数据进行预训练,将“直接”的空间推理能力注入 VLM。因此,我们合成了图像中涉及不超过两个对象(表示为“A”和“B”)的空间推理 QA 对,并考虑以下两类问题。
定性问题:要求判断某种空间关系的问题。例如“给定两个物体 A 和 B,哪个更靠左?”,“物体 A 比物体 B 更高吗?”和“A 和 B 中,哪个的宽度更大?”。
定量问题:要求更细粒度的答案,包括数字和单位。示例包括“物体 A 相对于物体 B 向左移动多少?”,“物体 A 距离 B 有多远?”,“找出 A 相对于相机位于 B 后面多远。”。与上述示例类似,此类问题可以使用主问题模板合成,并且可以在消除歧义后使用对象标题填充对象名称条目。此属性允许我们进行基于模板的生成,这是指令调整工作中常用的方法 [64]。
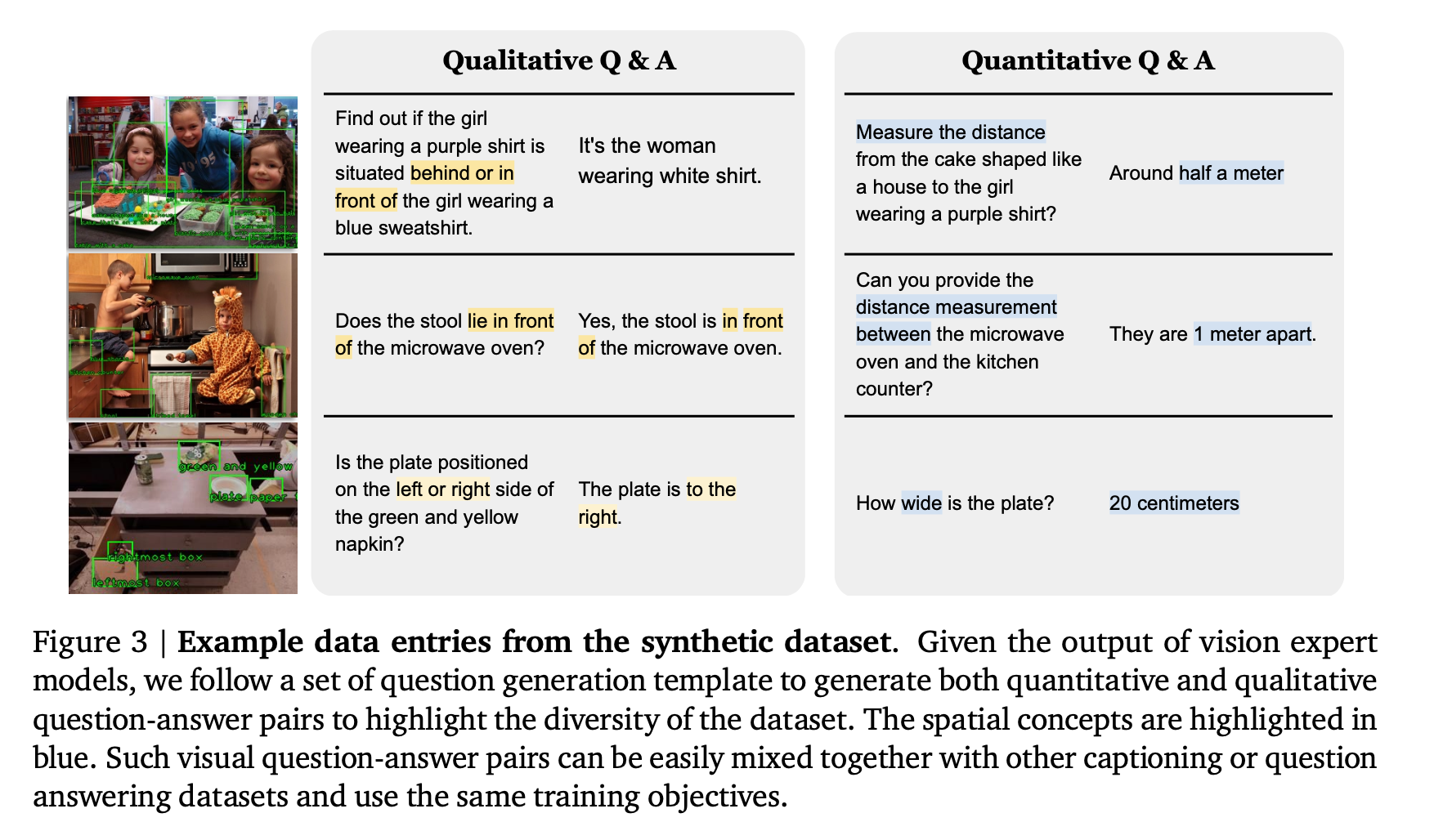
问题的答案是通过我们开发的适当函数获得的,这些函数将相关对象的分割点云和 3D 边界框作为输入。 我们指定了 38 种不同类型的定性和定量空间推理问题,每种问题都有大约 20 个问题模板和 10 个答案模板(我们在附录 A.3 中展示了示例)。 我们还增加了偏差采样以鼓励简洁的答案。最后,我们在附录 A.2 中引入了一种人性化的舍入机制,以类似人类的方式进行数字舍入。使用这种方法,我们能够为 webli 和 vqa 数据集中的单目相机图像生成充足的问答数据对。图 3 显示了我们获得的几个示例合成问答对。总的来说,我们创建了一个包含 1000 万张图像和 20 亿个直接空间推理 QA 对的庞大数据集,其中 50% 是定性问题,50% 是定量问题。由于对象标题和距离单位的多样性,我们的合成数据集在对象描述、问题类型和措辞方面具有显著的多样性。
3.3. Learning Spatial Reasoning
直接空间推理的定义如下:视觉语言模型将空间任务的图像 I 和查询 Q 作为输入,并以文本字符串的格式输出答案 A,而无需使用外部工具或与其他大型模型交互。我们采用与 PaLM-E [18] 相同的架构和训练程序,只是用较小的变体 PaLM 2-S [3] 替换了 PaLM [14] 主干。然后,我们使用原始 PaLM-E 数据集和我们的数据集的混合来训练我们的模型,其中 5% 的 token 专用于空间推理任务。与 PaLM-E 类似,我们的方法在结合使用时能够执行 VQA 以及基本的具身规划。关键的区别在于它可以回答有关二元谓词和定量估计的空间推理问题。
思维链空间推理:许多现实世界的任务需要多步空间推理。例如,要确定物体 A 是否适合物体 B,需要推理尺寸和约束。有时,人们需要推理扎实的空间概念(例如,图像中的柜台高 1 米)和常识知识(幼儿无法触及)。SpatialVLM 提供了一个自然语言界面,可以使用扎实的概念进行查询,当与强大的 LLM 结合使用时,我们可以执行复杂的空间推理。我们将这种方法称为“思维链空间推理”。虽然我们的合成数据仅包含直接的空间推理问题,但 VLM 很容易将它们组合在一起,以解决需要多跳思维链推理的复杂问题。与苏格拉底模型 [71] 和 LLM 作为协调员 [10] 中的方法类似,我们利用 LLM (text-davinci-003) 来协调和与我们的 SpatialVLM 通信,以解决具有思维链提示的复杂问题 [65],如图 4 所示。LLM 可以将复杂问题分解为简单问题,查询 VLM,并将推理放在一起得出结果。
